Stochastic Block Models
Contents
11.5. Stochastic Block Models#
11.5.1. A Priori Stochastic Block Model#
The a priori SBM is an SBM in which we know ahead of time (a priori) which nodes are in which communities. Here, we will use the variable \(K\) to denote the maximum number of different communities. The ordering of the communities does not matter; the community we call \(1\) versus \(2\) versus \(K\) is largely a symbolic distinction (the only thing that matters is that they are different). The a priori SBM has the following parameter:
Parameter |
Space |
Description |
|---|---|---|
\(B\) |
[0,1]\(^{K \times K}\) |
The block matrix, which assigns edge probabilities for pairs of communities |
To describe the A Priori SBM, we will designate the community each node is a part of using a vector, which has a single community assignment for each node in the network. We will call this node assignment vector \(\vec{\tau}\), and it is a \(n\)-length vector (one element for each node) with elements which can take values from \(1\) to \(K\). In symbols, we would say that \(\vec\tau \in \{1, ..., K\}^n\). What this means is that for a given element of \(\vec \tau\), \(\tau_i\), that \(\tau_i\) is the community assignment (either \(1\), \(2\), so on and so forth up to \(K\)) for the \(i^{th}\) node. If there we hahd an example where there were \(2\) communities (\(K = 2\)) for instance, and the first two nodes are in community \(1\) and the second two in community \(2\), then \(\vec\tau\) would be a vector which looks like:
Next, let’s discuss the matrix \(B\), which is known as the block matrix of the SBM. We write down that \(B \in [0, 1]^{K \times K}\), which means that the block matrix is a matrix with \(K\) rows and \(K\) columns. If we have a pair of nodes and know which of the \(K\) communities each node is from, the block matrix tells us the probability that those two nodes are connected. If our networks are simple, the matrix \(B\) is also symmetric, which means that if \(b_{kk'} = p\) where \(p\) is a probability, that \(b_{k'k} = p\), too. The requirement of \(B\) to be symmetric exists only if we are dealing with undirected networks.
Finally, let’s think about how to write down the generative model for the a priori SBM. Intuitionally what we want to reflect is, if we know that node \(i\) is in community \(k'\) and node \(j\) is in community \(k\), that the \((k', k)\) entry of the block matrix is the probability that \(i\) and \(j\) are connected. We say that given \(\tau_i = k'\) and \(\tau_j = k\), \(\mathbf a_{ij}\) is sampled independently from a \(Bern(b_{k' k})\) distribution for all \(j > i\). Note that the adjacencies \(\mathbf a_{ij}\) are not necessarily identically distributed, because the probability depends on the community of edge \((i,j)\). If \(\mathbf A\) is an a priori SBM network with parameter \(B\), and \(\vec{\tau}\) is a realization of the node-assignment vector, we write that \(\mathbf A \sim SBM_{n,\vec \tau}(B)\).
11.5.1.1. Probability#
What does the probability for the a priori SBM look like? In our previous description, we admittedly simplified things to an extent to keep the wording down. In truth, we model the a priori SBM using a latent variable model, which means that the node assignment vector, \(\vec{\pmb \tau}\), is treated as random. For the case of the a priori SBM, it just so happens that we know the specific value that this latent variable \(\vec{\pmb \tau}\) takes, \(\vec \tau\), ahead of time.
Fortunately, since \(\vec \tau\) is a parameter of the a priori SBM, the probability is a bit simpler than for the a posteriori SBM. This is because the a posteriori SBM requires an integration over potential realizations of \(\vec{\pmb \tau}\), whereas the a priori SBM does not, since we already know that \(\vec{\pmb \tau}\) was realized as \(\vec\tau\).
Putting these steps together gives us that:
Next, for the a priori SBM, we know that each edge \(\mathbf a_{ij}\) only actually depends on the community assignments of nodes \(i\) and \(j\), so we know that \(Pr_{\theta}(\mathbf a_{ij} = a_{ij} | \vec{\pmb \tau} = \vec\tau) = Pr(\mathbf a_{ij} = a_{ij} | \tau_i = k', \tau_j = k)\), where \(k\) and \(k'\) are any of the \(K\) possible communities. This is because the community assignments of nodes that are not nodes \(i\) and \(j\) do not matter for edge \(ij\), due to the independence assumption.
Next, let’s think about the probability matrix \(P = (p_{ij})\) for the a priori SBM. We know that, given that \(\tau_i = k'\) and \(\tau_j = k\), each adjacency \(\mathbf a_{ij}\) is sampled independently and identically from a \(Bern(b_{k',k})\) distribution. This means that \(p_{ij} = b_{k',k}\). Completing our analysis from above:
Where \(n_{k' k}\) denotes the total number of edges possible between nodes assigned to community \(k'\) and nodes assigned to community \(k\). That is, \(n_{k' k} = \sum_{j > i} \mathbb 1_{\tau_i = k'}\mathbb 1_{\tau_j = k}\). Further, we will use \(m_{k' k}\) to denote the total number of edges observed between these two communities. That is, \(m_{k' k} = \sum_{j > i}\mathbb 1_{\tau_i = k'}\mathbb 1_{\tau_j = k}a_{ij}\). Note that for a single \((k',k)\) community pair, that the probability is analogous to the probability of a realization of an ER random variable.
Like the ER model, there are again equivalence classes of the sample space \(\mathcal A_n\) in terms of their probability. For a two-community setting, with \(\vec \tau\) and \(B\) given, the equivalence classes are the sets:
The number of equivalence classes possible scales with the number of communities, and the manner in which nodes are assigned to communities (particularly, the number of nodes in each community).
11.5.2. A Posteriori Stochastic Block Model#
In the a posteriori Stochastic Block Model (SBM), we consider that node assignment to one of \(K\) communities is a random variable, that we don’t know already like te a priori SBM. We’re going to see a funky word come up, that you’re probably not familiar with, the \(K\) probability simplex. What the heck is a probability simplex?
The intuition for a simplex is probably something you’re very familiar with, but just haven’t seen a word describe. Let’s say I have a vector, \(\vec\pi = (\pi_k)_{k \in [K]}\), which has a total of \(K\) elements. \(\vec\pi\) will be a vector, which indicates the probability that a given node is assigned to each of our \(K\) communities, so we need to impose some additional constraints. Symbolically, we would say that, for all \(i\), and for all \(k\):
The \(\vec \pi\) we’re going to use has a very special property: all of its elements are non-negative: for all \(\pi_k\), \(\pi_k \geq 0\). This makes sense since \(\pi_k\) is being used to represent the probability of a node \(i\) being in group \(k\), so it certainly can’t be negative. Further, there’s another thing that we want our \(\vec\pi\) to have: in order for each element \(\pi_k\) to indicate the probability of something to be assigned to \(k\), we need all of the \(\pi_k\)s to sum up to one. This is because of something called the Law of Total Probability. If we have \(K\) total values that \(\pmb \tau_i\) could take, then it is the case that:
So, back to our question: how does a probability simplex fit in? Well, the \(K\) probability simplex describes all of the possible values that our vector \(\vec\pi\) could take! In symbols, the \(K\) probability simplex is:
So the \(K\) probability simplex is just the space for all possible vectors which could indicate assignment probabilities to one of \(K\) communities.
What does the probability simplex look like? Below, we take a look at the \(2\)-probability simplex (2-d \(\vec\pi\)s) and the \(3\)-probability simplex (3-dimensional \(\vec\pi\)s):
from mpl_toolkits.mplot3d import Axes3D
from mpl_toolkits.mplot3d.art3d import Poly3DCollection
import matplotlib.pyplot as plt
fig=plt.figure(figsize=plt.figaspect(.5))
fig.suptitle("Probability Simplexes")
ax=fig.add_subplot(1,2,1)
x=[1,0]
y=[0,1]
ax.plot(x,y)
ax.set_xticks([0,.5,1])
ax.set_yticks([0,.5,1])
ax.set_xlabel("$\pi_1$")
ax.set_ylabel("$\pi_2$")
ax.set_title("2-probability simplex")
ax=fig.add_subplot(1,2,2,projection='3d')
x = [1,0,0]
y = [0,1,0]
z = [0,0,1]
verts = [list(zip(x,y,z))]
ax.add_collection3d(Poly3DCollection(verts, alpha=.6))
ax.view_init(elev=20,azim=10)
ax.set_xticks([0,.5,1])
ax.set_yticks([0,.5,1])
ax.set_zticks([0,.5,1])
ax.set_xlabel("$\pi_1$")
ax.set_ylabel("$\pi_2$")
h=ax.set_zlabel("$\pi_3$", rotation=0)
ax.set_title("3-probability simplex")
plt.show()
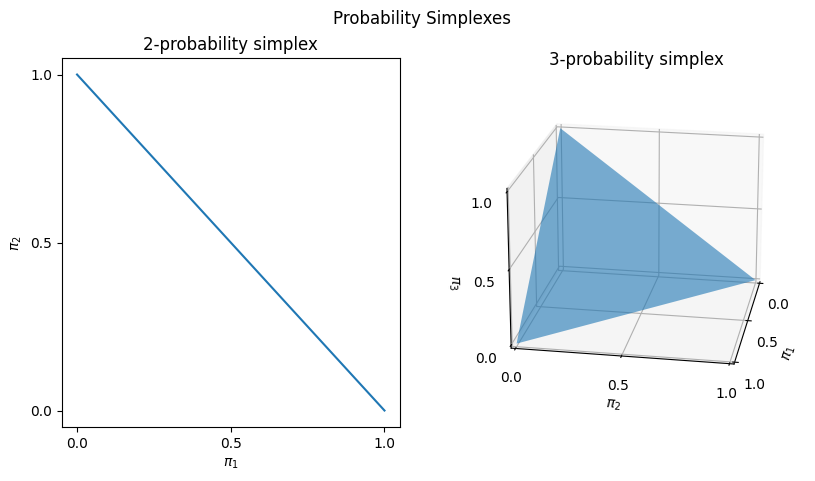
The values of \(\vec\pi = (\pi)\) that are in the \(K\)-probability simplex are indicated by the shaded region of each figure. This comprises the \((\pi_1, \pi_2)\) pairs that fall along a diagonal line from \((0,1)\) to \((1,0)\) for the \(2\)-simplex, and the \((\pi_1, \pi_2, \pi_3)\) tuples that fall on the surface of the triangular shape above with nodes at \((1,0,0)\), \((0,1,0)\), and \((0,0,1)\).
This model has the following parameters:
Parameter |
Space |
Description |
|---|---|---|
\(\vec \pi\) |
the \(K\) probability simplex |
The probability of a node being assigned to community \(K\) |
\(B\) |
[0,1]\(^{K \times K}\) |
The block matrix, which assigns edge probabilities for pairs of communities |
The a posteriori SBM is a bit more complicated than the a priori SBM. We will think about the a posteriori SBM as a variation of the a priori SBM, where instead of the node-assignment vector being treated as a known fixed value (the community assignments), we will treat it as unknown. \(\vec{\pmb \tau}\) is called a latent variable, which means that it is a quantity that is never actually observed, but which will be useful for describing our model. In this case, \(\vec{\pmb \tau}\) takes values in the space \(\{1,...,K\}^n\). This means that for a given realization of \(\vec{\pmb \tau}\), denoted by \(\vec \tau\), that for each of the \(n\) nodes in the network, we suppose that an integer value between \(1\) and \(K\) indicates which community a node is from. Statistically, we write that the node assignment for node \(i\), denoted by \(\pmb \tau_i\), is sampled independently and identically from \(Categorical(\vec \pi)\). Stated another way, the vector \(\vec\pi\) indicates the probability \(\pi_k\) of assignment to each community \(k\) in the network.
The matrix \(B\) behaves exactly the same as it did with the a posteriori SBM. Finally, let’s think about how to write down the generative model in the a posteriori SBM. The model for the a posteriori SBM is, in fact, nearly the same as for the a priori SBM: we still say that given \(\tau_i = k'\) and \(\tau_j = k\), that \(\mathbf a_{ij}\) are independent \(Bern(b_{k'k})\). Here, however, we also describe that \(\pmb \tau_i\) are sampled independent and identically from \(Categorical(\vec\pi)\), as we learned above. If \(\mathbf A\) is the adjacency matrix for an a posteriori SBM network with parameters \(\vec \pi\) and \(B\), we write that \(\mathbf A \sim SBM_n(\vec \pi, B)\).
11.5.2.1. Probability#
What does the probability for the a posteriori SBM look like? In this case, \(\theta = (\vec \pi, B)\) are the parameters for the model, so the probability for a realization \(A\) of \(\mathbf A\) is:
Next, we use the fact that the probability that \(\mathbf A = A\) is, in fact, the integration (over realizations of \(\vec{\pmb \tau}\)) of the joint \((\mathbf A, \vec{\pmb \tau})\). In this case, we will let \(\mathcal T = \{1,...,K\}^n\) be the space of all possible realizations that \(\vec{\pmb \tau}\) could take:
Next, remember that by definition of a conditional probability for a random variable \(\mathbf x\) taking value \(x\) conditioned on random variable \(\mathbf y\) taking the value \(y\), that \(Pr(\mathbf x = x | \mathbf y = y) = \frac{Pr(\mathbf x = x, \mathbf y = y)}{Pr(\mathbf y = y)}\). Note that by multiplying through by \(\mathbf P(\mathbf y = y)\), we can see that \(Pr(\mathbf x = x, \mathbf y = y) = Pr(\mathbf x = x| \mathbf y = y)Pr(\mathbf y = y)\). Using this logic for \(\mathbf A\) and \(\vec{\pmb \tau}\):
Intuitively, for each term in the sum, we are treating \(\vec{\pmb \tau}\) as taking a fixed value, \(\vec\tau\), to evaluate this probability statement.
We will start by describing \(Pr(\vec{\pmb \tau} = \vec\tau)\). Remember that for \(\vec{\pmb \tau}\), that each entry \(\pmb \tau_i\) is sampled independently and identically from \(Categorical(\vec \pi)\).The probability mass for a \(Categorical(\vec \pi)\)-valued random variable is \(Pr(\pmb \tau_i = \tau_i; \vec \pi) = \pi_{\tau_i}\). Finally, note that if we are taking the products of \(n\) \(\pi_{\tau_i}\) terms, that many of these values will end up being the same. Consider, for instance, if the vector \(\tau = [1,2,1,2,1]\). We end up with three terms of \(\pi_1\), and two terms of \(\pi_2\), and it does not matter which order we multiply them in. Rather, all we need to keep track of are the counts of each \(\pi\) term. Written another way, we can use the indicator that \(\tau_i = k\), given by \(\mathbb 1_{\tau_i = k}\), and a running counter over all of the community probability assignments \(\pi_k\) to make this expression a little more sensible. We will use the symbol \(n_k = \sum_{i = 1}^n \mathbb 1_{\tau_i = k}\) to denote this value, which is the number of nodes in community \(k\):
Next, let’s think about the conditional probability term, \(Pr_\theta(\mathbf A = A \big | \vec{\pmb \tau} = \vec \tau)\). Remember that the entries are all independent conditional on \(\vec{\pmb \tau}\) taking the value \(\vec\tau\). It turns out this is exactly the same result that we obtained for the a priori SBM:
Combining these into the integrand gives:
Evaluating this sum explicitly proves to be relatively tedious and is a bit outside of the scope of this book, so we will omit it here.
11.5.3. Degree-Corrected Stochastic Block Model (DCSBM)#
Let’s think back to our school example for the Stochastic Block Model. Remember, we had 100 students, each of whom could go to one of two possible schools: school one or school two. Our network had 100 nodes, representing each of the students. We said that the school for which each student attended was represented by their node assignment \(\tau_i\) to one of two possible communities. The matrix \(B\) was the block probaability matrix, where \(b_{11}\) was the probability that students in school one were friends, \(b_{22}\) was the probability that students in school two were friends, and \(b_{12} = b_{21}\) was the probability that students were friends if they did not go to the same school. In this case, we said that \(\mathbf A\) was an \(SBM_n(\tau, B)\) random network.
When would this setup not make sense? Let’s say that Alice and Bob both go to the same school, but Alice is more popular than Bob. In general since Alice is more popular than Bob, we might want to say that for any clasasmate, Alice gets an additional “popularity benefit” to her probability of being friends with the other classmate, and Bob gets an “unpopularity penalty.” The problem here is that within a single community of an SBM, the SBM assumes that the node degree (the number of nodes each nodes is connected to) is the same for all nodes within a single community. This means that we would be unable to reflect this benefit/penalty system to Alice and Bob, since each student will have the same number of friends, on average. This problem is referred to as community degree homogeneity in a Stochastic Block Model Network. Community degree homogeneity just means that the node degree is homogeneous, or the same, for all nodes within a community.
Degree Homogeneity in a Stochastic Block Model Network
Suppose that \(\mathbf A \sim SBM_{n, \vec\tau}(B)\), where \(\mathbf A\) has \(K=2\) communities. What is the node degree of each node in \(\mathbf A\)?
For an arbitrary node \(v_i\) which is in community \(k\) (either one or two), we will compute the expectated value of the degree \(deg(v_i)\), written \(\mathbb E\left[deg(v_i); \tau_i = k\right]\). We will let \(n_k\) represent the number of nodes whose node assignments \(\tau_i\) are to community \(k\). Let’s see what happens:
We use the linearity of expectation again to get from the top line to the second line. Next, instead of summing over all the nodes, we’ll break the sum up into the nodes which are in the same community as node \(i\), and the ones in the other community \(k'\). We use the notation \(k'\) to emphasize that \(k\) and \(k'\) are different values:
In the first sum, we have \(n_k-1\) total edges (the number of nodes that aren’t node \(i\), but are in the same community), and in the second sum, we have \(n_{k'}\) total edges (the number of nodes that are in the other community). Finally, we will use that the probability of an edge in the same community is \(b_{kk}\), but the probability of an edge between the communities is \(b_{k' k}\). Finally, we will use that the expected value of an adjacency \(\mathbf a_{ij}\) which is Bernoulli distributed is its probability:
This holds for any node \(i\) which is in community \(k\). Therefore, the expected node degree is the same, or homogeneous, within a community of an SBM.
To address this limitation, we turn to the Degree-Corrected Stochastic Block Model, or DCSBM. As with the Stochastic Block Model, there is both a a priori and a posteriori DCSBM.
11.5.3.1. A Priori DCSBM#
Like the a priori SBM, the a priori DCSBM is where we know which nodes are in which communities ahead of time. Here, we will use the variable \(K\) to denote the number of different communiies. The a priori DCSBM has the following two parameters:
Parameter |
Space |
Description |
|---|---|---|
\(B\) |
[0,1]\(^{K \times K}\) |
The block matrix, which assigns edge probabilities for pairs of communities |
\(\vec\theta\) |
\(\mathbb R^n_+\) |
The degree correction vector, which adjusts the degree for pairs of nodes |
The latent community assignment vector \(\vec{\pmb \tau}\) with a known a priori realization \(\vec{\tau}\) and the block matrix \(B\) are exactly the same for the a priori DCSBM as they were for the a priori SBM.
The vector \(\vec\theta\) is the degree correction vector. Each entry \(\theta_i\) is a positive scalar. \(\theta_i\) defines how much more (or less) edges associated with node \(i\) are connected due to their association with node \(i\).
Finally, let’s think about how to write down the generative model for the a priori DCSBM. We say that \(\tau_i = k'\) and \(\tau_j = k\), \(\mathbf a_{ij}\) is sampled independently from a \(Bern(\theta_i \theta_j b_{k'k})\) distribution for all \(j > i\). As we can see, \(\theta_i\) in a sense is “correcting” the probabilities of each adjacency to node \(i\) to be higher, or lower, depending on the value of \(\theta_i\) that that which is given by the block probabilities \(b_{\ell k}\). If \(\mathbf A\) is an a priori DCSBM network with parameters and \(B\), we write that \(\mathbf A \sim DCSBM_{n,\vec\tau}(\vec \theta, B)\).
11.5.3.1.1. Probability#
The derivation for the probability is the same as for the a priori SBM, with the change that \(p_{ij} = \theta_i \theta_j b_{k'k}\) instead of just \(b_{k'k}\). This gives that the probability turns out to be:
The expression doesn’t simplify much more due to the fact that the probabilities are dependent on the particular \(i\) and \(j\), so we can’t just reduce the statement in terms of \(n_{k'k}\) and \(m_{k'k}\) like for the SBM.
11.5.3.2. A Posteriori DCSBM#
The a posteriori DCSBM is to the a posteriori SBM what the a priori DCSBM was to the a priori SBM. The changes are very minimal, so we will omit explicitly writing it all down here so we can get this section wrapped up, with the idea that the preceding section on the a priori DCSBM should tell you what needs to change. We will leave it as an exercise to the reader to write down a model and probability statement for realizations of the DCSBM.