Random Dot Product Graphs (RDPG)
Contents
4.3. Random Dot Product Graphs (RDPG)#
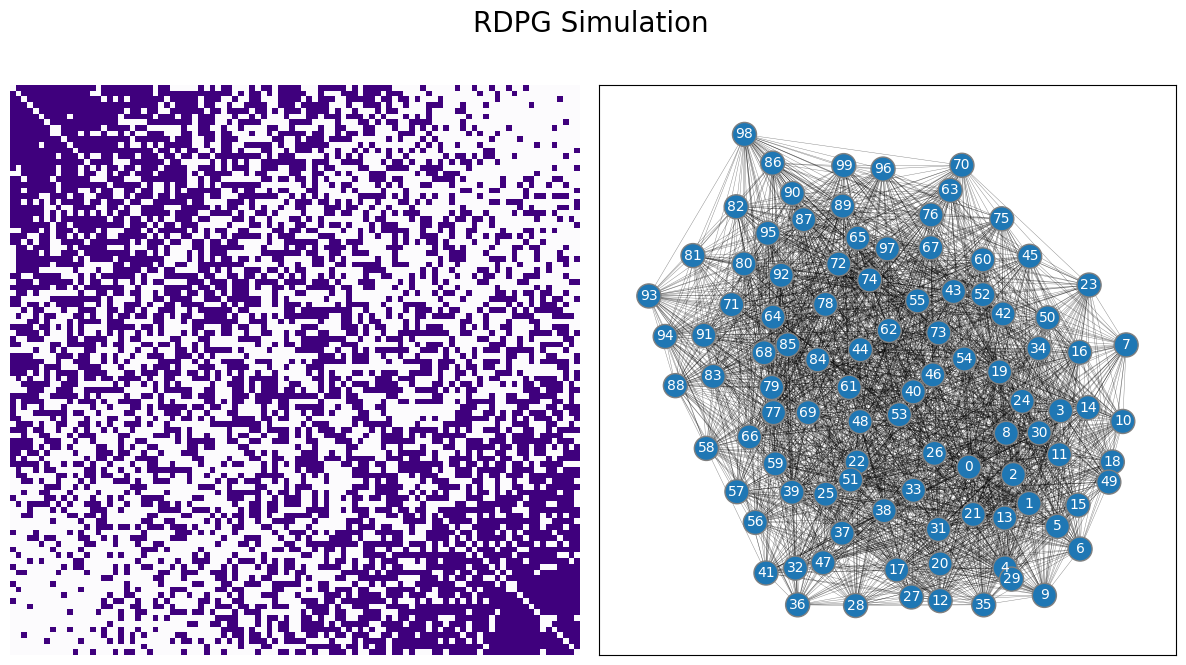
In this section, you are going to learn about the Random Dot Product Graph (RDPG), a further generalization of the random network models you have studied. This concept was first introduced by [1]. With the RDPG, you can have random networks which are much more complex than those you saw with the ER and the SBM random neworks, but still have a discernable structure to them. For example, here’s a sample from an RDPG random network:
import numpy as np
from graspologic.simulations import rdpg
from graphbook_code import draw_multiplot
n = 100 # the number of nodes in your network
# design the latent position matrix X according to
# the rules we laid out previously
X = np.zeros((n,2))
for i in range(0, n):
X[i,:] = [(n - i)/n, i/n]
from graspologic.simulations import rdpg
from graphbook_code import draw_multiplot
A = rdpg(X, directed=False, loops=False)
draw_multiplot(A, title="RDPG Simulation");
4.3.1. Rethinking the Stochastic Block Model with a probability matrix#
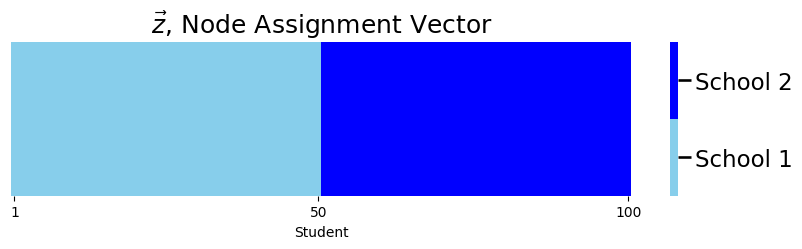
Let’s imagine that you have a network which follows the Stochastic Block Model. To make this example a little bit more concrete, let’s borrow the code example from Stochastic Block Models (SBM). The nodes of your network represent each of the \(100\) students. Remember that \(\vec z\) is the community assignment vector, which indicates which community (one of two schools) each node (student) is in. Here, the first \(50\) students attend school \(1\), and the second \(50\) students attend school \(2\):
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import matplotlib
def plot_tau(tau, title="", xlab="Node"):
cmap = matplotlib.colors.ListedColormap(["skyblue", 'blue'])
fig, ax = plt.subplots(figsize=(10,2))
with sns.plotting_context("talk", font_scale=1):
ax = sns.heatmap((tau - 1).reshape((1,tau.shape[0])), cmap=cmap,
ax=ax, cbar_kws=dict(shrink=1), yticklabels=False,
xticklabels=False)
ax.set_title(title)
cbar = ax.collections[0].colorbar
cbar.set_ticks([0.25, .75])
cbar.set_ticklabels(['School 1', 'School 2'])
ax.set(xlabel=xlab)
ax.set_xticks([.5,49.5,99.5])
ax.set_xticklabels(["1", "50", "100"])
cbar.ax.set_frame_on(True)
return
n = 100 # number of students
# tau is a column vector of 150 1s followed by 50 2s
# this vector gives the school each of the 300 students are from
zvec = np.vstack((np.ones((int(n/2),1)), np.full((int(n/2),1), 2)))
plot_tau(zvec, title="$\\vec z$, Node Assignment Vector",
xlab="Student")
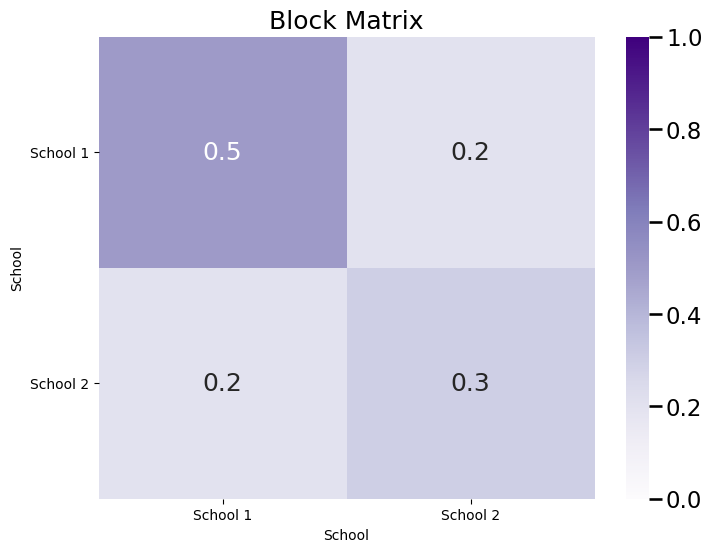
And the block probability matrix \(B\) is a \(2 \times 2\) matrix, where each entry \(b_{kl}\) indicates the probability that a node assigned to community \(k\) is connected to a node assigned to community \(l\):
K = 2 # 2 communities in total
# construct the block matrix B as described above
B = [[0.5, 0.2], [0.2, 0.3]]
def plot_block(X, title="", blockname="School", blocktix=[0.5, 1.5],
blocklabs=["School 1", "School 2"]):
fig, ax = plt.subplots(figsize=(8, 6))
with sns.plotting_context("talk", font_scale=1):
ax = sns.heatmap(X, cmap="Purples",
ax=ax, cbar_kws=dict(shrink=1), yticklabels=False,
xticklabels=False, vmin=0, vmax=1, annot=True)
ax.set_title(title)
cbar = ax.collections[0].colorbar
ax.set(ylabel=blockname, xlabel=blockname)
ax.set_yticks(blocktix)
ax.set_yticklabels(blocklabs)
ax.set_xticks(blocktix)
ax.set_xticklabels(blocklabs)
cbar.ax.set_frame_on(True)
return
plot_block(B, title="Block Matrix")
plt.show()
Are there any other ways to describe this scenario, other than using both the community assignment vector \(\vec z\) and the block matrix \(B\)?
4.3.1.1. Probability matrices explicitly state the probability for each edge#
Remember, for a given \(\vec z\) and \(B\), that a network which is SBM can be generated using the approach that, given that \(z_i = \ell\) and \(z_j = k\), each edge \((i, j)\) comes down to a coin flip, where the edge exists if the coin lands on heads with probability \(b_{z_i z_j}\) or does not exist if the coin lands on tails with probability \(1- b_{z_i z_j}\). However, there’s another way you could write down this generative model. Suppose you had a \(n \times n\) probability matrix, where for every \(j > i\):
This matrix \(P\) with entries \(p_{ij}\) is the probability matrix associated with the SBM. Simply put, this matrix describes the probability \(p_{ij}\) of each edge \((i,j)\) between nodes \(i\) and \(j\) existing. What does \(P\) look like?
import pandas as pd
def plot_prob(X, title="", nodename="Student", nodetix=None,
nodelabs=None, ax=None):
if (ax is None):
fig, ax = plt.subplots(figsize=(8, 6))
with sns.plotting_context("talk", font_scale=1):
ax = sns.heatmap(X, cmap="Purples",
ax=ax, cbar_kws=dict(shrink=1), yticklabels=False,
xticklabels=False, vmin=0, vmax=1, annot=False)
ax.set_title(title)
cbar = ax.collections[0].colorbar
ax.set(ylabel=nodename, xlabel=nodename)
if (nodetix is not None) and (nodelabs is not None):
ax.set_yticks(nodetix)
ax.set_yticklabels(nodelabs)
ax.set_xticks(nodetix)
ax.set_xticklabels(nodelabs)
cbar.ax.set_frame_on(True)
return
def plot_prob_block_annot(X, title="", nodename="Student", nodetix=None,
nodelabs=None, ax=None):
if (ax is None):
fig, ax = plt.subplots(figsize=(8, 6))
with sns.plotting_context("talk", font_scale=1):
X_annot = np.empty((100, 100), dtype='U3')
X_annot[25, 25] = '0.5'
X_annot[75, 75] = '0.3'
X_annot[25,75] = '0.2'
X_annot[75, 25] = '0.2'
ax = sns.heatmap(X, cmap="Purples",
ax=ax, cbar_kws=dict(shrink=1), yticklabels=False,
xticklabels=False, vmin=0, vmax=1, annot=pd.DataFrame(X_annot),
fmt='')
ax.set_title(title)
cbar = ax.collections[0].colorbar
ax.set(ylabel=nodename, xlabel=nodename)
if (nodetix is not None) and (nodelabs is not None):
ax.set_yticks(nodetix)
ax.set_yticklabels(nodelabs)
ax.set_xticks(nodetix)
ax.set_xticklabels(nodelabs)
cbar.ax.set_frame_on(True)
return
P = np.zeros((n,n))
P[0:50,0:50] = .5
P[50:100, 50:100] = .3
P[0:50,50:100] = .2
P[50:100,0:50] = .2
ax = plot_prob_block_annot(P, title="Probability Matrix", nodetix=[0,100],
nodelabs=["1", "100"])
plt.show()
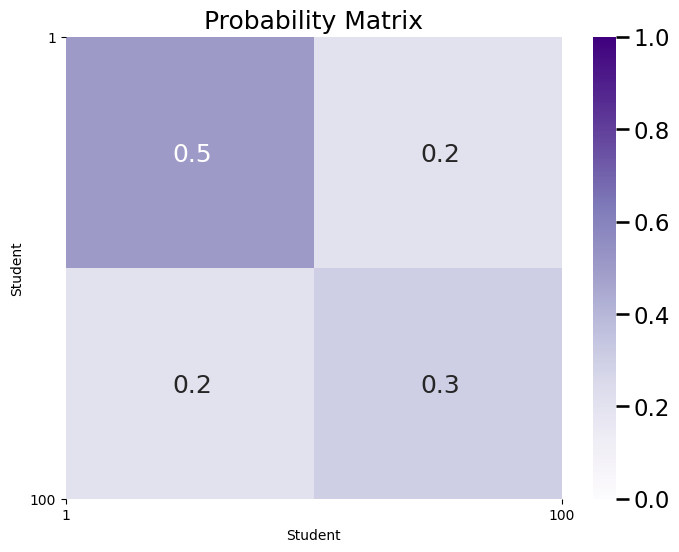
As you can see, \(P\) captures a similar modular structure to the actual adjacency matrix corresponding to the SBM network. When we say this network is modular, we mean that it looks block-y, in that there are clusters of edges sharing a similar probability. Also, \(P\) captures the probability of connections between each pair of students. It is the case that \(P\) contains the information of both \(\vec z\) and \(B\). This means that you can write down a generative model by specifying only \(P\), and you no longer need to specify \(\vec z\) nor \(B\) at all.
To represent an SBM random network using \(P\) uses a lot more space than using the community assignment vector \(\vec z\) and the block matrix \(B\) alone: \(\vec z\) has \(n\) entries, and \(B\) has \(K \times K\) entries, where \(K\) is typically much smaller than \(n\). On the other hand, in this formulation, \(P\) has \(\binom{n}{2}\) entries, which is much bigger than \(n + K \times K\) (since \(K\) is usually much smaller than \(n\), because you usually want the communities to be meaningful groupings of many nodes). One thing you might be wondering, however, is can you make things even more general by using \(P\) instead of \(\vec z\) and \(B\)? As you can see in your probability matrix above, there are only \(4\) unique entries in total! Can you make \(P\) any more general, and still have a statistical model that simplifies the network with fewer than \(\binom{n}{2}\) entries?
4.3.1.2. Decomposing the probability matrix into simpler components#
As it turns out, for a Stochastic Block Model, the probability matrix \(P\) can be decomposed using a matrix \(X\), where \(P = X X^\top\). This matrix \(X\) is a special matrix called the latent position matrix, which you will study in much deeper depth in this section and in Learning Network Representations. We will call a single row of \(X\) the vector \(\vec x_i\). Using this expression, each entry \(p_{ij}\) is going to end up being the product \(\vec x_i^\top \vec x_j\), for all \(i, j\). Like \(P\), \(X\) has \(n\) rows, each of which corresponds to a single node in your network. However, the special property of \(X\) is that it doesn’t necessarily have \(n\) columns: rather, \(X\) often will have many fewer columns than rows. For instance, with \(P\) from the example above on Stochastic Block Models, there in fact exists an \(X\) with just \(2\) columns that can be used to describe \(P\). Let’s take a look at what \(X\) looks like. You won’t learn how to compute this \(X\) just yet, but we’ll try to build some insight into what’s going on here:
from numpy.linalg import svd
from graphbook_code import cmaps
U, S, V = svd(P)
X = U[:,0:2] @ np.sqrt(np.diag(S[0:2]))
def plot_latent(X, title="", nodename="Student", ylabel="Latent Dimension",
nodetix=None, nodelabs=None, dimtix=None, dimlabs=None):
fig, ax = plt.subplots(figsize=(3, 6))
with sns.plotting_context("talk", font_scale=1):
lim_max = np.max(np.abs(X))
vmin = -lim_max; vmax = lim_max
X_annot = np.empty((100, 2), dtype='U6')
X_annot[25,0] = str("{:.3f}".format(X[25,0]))
X_annot[75,0] = str("{:.3f}".format(X[75,0]))
X_annot[25,1] = str("{:.3f}".format(X[25,1]))
X_annot[75,1] = str("{:.3f}".format(X[75,1]))
ax = sns.heatmap(X, cmap=cmaps["divergent"],
ax=ax, cbar_kws=dict(shrink=1), yticklabels=False,
xticklabels=False, vmin=vmin, vmax=vmax,
annot=X_annot, fmt='')
ax.set_title(title)
cbar = ax.collections[0].colorbar
ax.set(ylabel=nodename, xlabel=ylabel)
if (nodetix is not None) and (nodelabs is not None):
ax.set_yticks(nodetix)
ax.set_yticklabels(nodelabs)
if (dimtix is not None) and (dimlabs is not None):
ax.set_xticks(dimtix)
ax.set_xticklabels(dimlabs)
cbar.ax.set_frame_on(True)
return
ax = plot_latent(X, title="Latent Position Matrix", nodetix=[0, 49, 99],
nodelabs=["1", "50", "100"], dimtix=[0.5,1.5], dimlabs=["1", "2"])
plt.show()
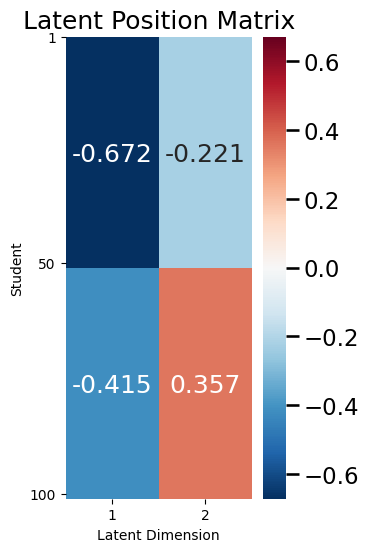
One thing we will come back to in a second is the fact that \(X\) in this case is relatively simple: there are only \(4\) unique entries, even though there are \(200\) total entries in \(X\) (2 columns for each of \(100\) students).
Like we said previously, it turns out that \(P\) can be described using only this matrix \(X\), as \(P = XX^\top\). Let’s see this in action, by comparing the \(P\) you had above to \(XX^\top\):
P_XXt = X @ X.T
fig, axs = plt.subplots(1, 2, figsize=(15, 6))
plot_prob_block_annot(P,
title="$P$",
ax=axs[0], nodetix=[0,100],
nodelabs=["1", "100"])
plot_prob_block_annot(P_XXt,
title="$XX^T$",
ax=axs[1], nodetix=[0,100],
nodelabs=["1", "100"])
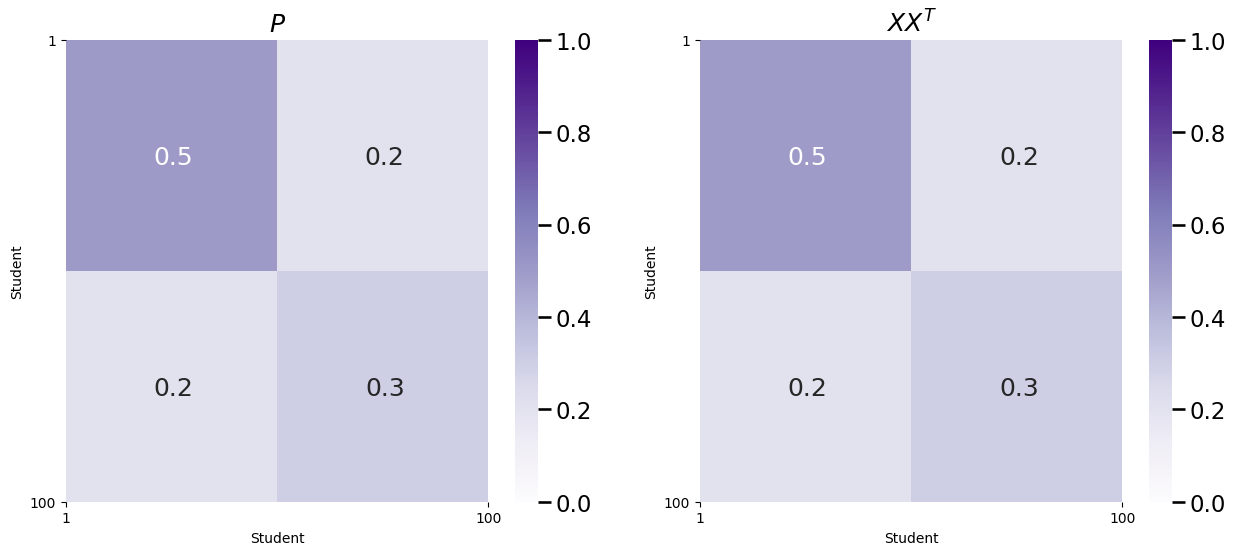
As you can see, \(P\) and \(XX^\top\) are identical!
Describing the probability matrix with this matrix \(X\) lends itself to an even further generalization of your single network models. Like we said a few figures ago, \(X\) only has \(4\) unique entries, but there is no reason for this restriction really. The matrix \(X\) can have any number of unique entries, so long as the product of \(X\) and its transpose, \(XX^\top\), ends up being a probability matrix (every entry is a number between \(0\) and \(1\)).
4.3.1.3. The Latent position matrix#
This matrix \(X\) is called the latent position matrix, and each row \(\vec x_i\) will be called the latent position of the node \(i\). In matrix form, \(X\) looks like this:
We will call the columns of \(X\) the latent dimensions, and the total number of columns that \(X\) has will be called the latent dimensionality. We will often use the letter \(d\) to denote the latent dimensionality of the latent position matrix \(X\). For this reason, you say that \(X\) is an \(n\) row (one for each node) and \(d\) column (one for each latent dimension) matrix. Therefore, the latent position of the node \(i\), \(\vec x_i\), is a \(d\)-dimensional vector. In a few words, the latent dimensionality describes the complexity that the resulting probability matrix \(P = XX^\top\) has: if there are more latent dimensions, \(P\) can look much more complicated than what you have seen thus far!
Let’s think about the latent position matrix in the context of our previous example with the SBM. A common way to explore the latent position matrix is to look at a heatmap (like we did above) or a scatter plot of the latent position matrix. Let’s think about what the scatter plot might look like. The latent dimensionality of the latent position matrix for the SBM example, it turns out, is \(2\), because you have two total latent dimensions for your latent position matrix \(X\). You will take the latent dimensions, and make the first latent dimension the \(x\)-axis, and the second latent dimension the \(y\)-axis. We next plot, for each node \(i\), a single point, whose \(x\)-coordinate will be the first latent dimension for the latent position of node \(i\), and the \(y\)-coordinate will be the second latent dimension for the latent position of node \(i\). In symbols, you will plot \((x_{i1}, x_{i2})\), for each node \(i\). This means that there will be \(n\)-total points shown in the plot below:
def plot_latent_hm_sc(X, title="", nodename="Student", ylabel="Latent Dimension",
nodetix=None, nodelabs=None, dimtix=None, dimlabs=None):
fig, axs = plt.subplots(1, 2, figsize=(12, 6), gridspec_kw={"width_ratios": [1.5, 3]})
fig.tight_layout(pad=6)
with sns.plotting_context("talk", font_scale=1):
lim_max = np.max(np.abs(X))
vmin = -lim_max; vmax = lim_max
X_annot = np.empty((100, 2), dtype='U6')
X_annot[25,0] = str("{:.3f}".format(X[25,0]))
X_annot[75,0] = str("{:.3f}".format(X[75,0]))
X_annot[25,1] = str("{:.3f}".format(X[25,1]))
X_annot[75,1] = str("{:.3f}".format(X[75,1]))
axs[0] = sns.heatmap(X, cmap=cmaps["divergent"],
ax=axs[0], cbar_kws=dict(shrink=1), yticklabels=False,
xticklabels=False, vmin=vmin, vmax=vmax,
annot=X_annot, fmt='')
axs[0].set_title("Latent Positions as Heatmap")
cbar = axs[0].collections[0].colorbar
axs[0].set(ylabel=nodename, xlabel=ylabel)
axs[0].set_yticks([0, 49, 99])
axs[0].set_yticklabels(["1", "50", "100"])
axs[0].set_xticks([0.5, 1.5])
axs[0].set_xticklabels(["1", "2"])
cbar.ax.set_frame_on(True)
X_df = pd.DataFrame(X)
X_df = X_df.rename(columns={0: "Latent Dimension 1", 1: "Latent Dimension 2"})
comm_list = ["1" if x < 50 else "2" for x in range(0, 100)]
X_df["School"] = comm_list
sns.scatterplot(data=X_df, x="Latent Dimension 1", y="Latent Dimension 2", hue="School")
axs[1].set_title("Latent Positions as Scatterplot")
return
plot_latent_hm_sc(X)
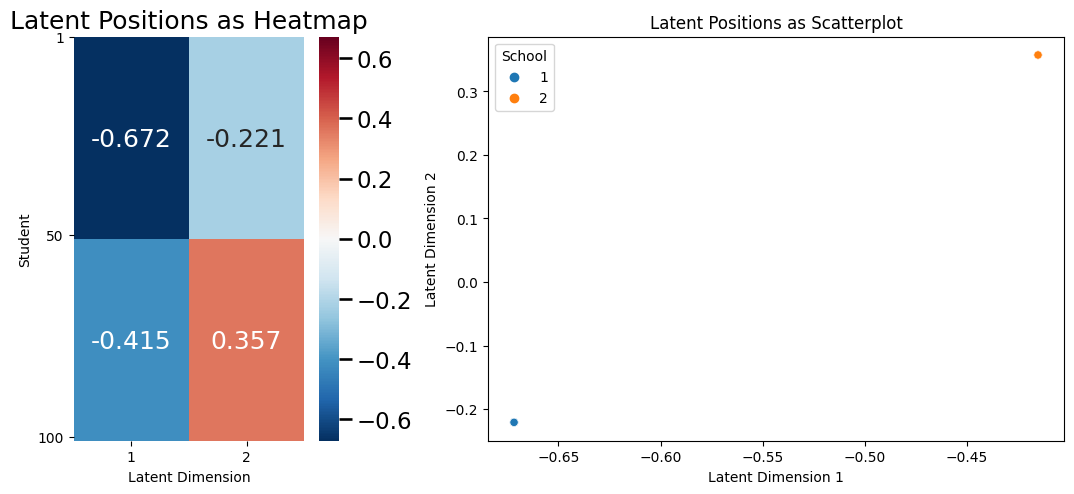
Why does your scatter plot look like it only has \(2\) points on it? Quite simply, for an SBM, every node within the same community has an identical latent position! This means that all of the nodes representing students who are in school \(1\) have the same latent positition vector as the other students in school \(1\). Similarly, all of the nodes representing students who are in school \(2\) have the same latent position vector as the other students in school \(2\). Even though it looks like there is only \(1\) point for each school community, there are really \(50\) total latent position vectors for each student within that community and they just happen to overlap. This does not need to be the case for the latent positions, as you will see in a more complicated example later on.
4.3.2. The Random Dot Product Graph (RDPG) is parametrized by a latent position matrix#
Now that we have some intuition built up, let’s circle back to random networks. We will call this particular network model the Random Dot Product Graph (RDPG) model. You call it the RDPG because the probabilities of edges existing are based on dot products between pairs of latent positions for the different nodes in the network. The way that you can think of the RDPG random network is that the edges depend on a latent position matrix \(X\). For each pair of nodes \(i\) and \(j\), you have a unique coin (we will call this the \((i,j)\) coin) which has a \(\vec x_i^\top \vec x_j\) chance of landing on heads, and a \(1 - \vec x_i^\top \vec x_j\) chance of landing on tails. If the \((i,j)\) coin lands on heads, the edge between nodes \(i\) and \(j\) exists, and if the \((i,j)\) coin lands on tails, the edge between nodes \(i\) and \(j\) does not exist. As before, this coin flip is performed independent of the coin flips for all of the other edges. The notation you use here is just what you are used to in the preceding sections. If \(\mathbf A\) is a random network which is \(RDPG\) with a latent position matrix \(X\), we say that \(\mathbf A\) is an \(RDPG_n(X)\) random network.
4.3.3. How do you simulate samples of \(RDPG_n(X)\) random networks?#
The procedure below will produce for you a network \(A\), which has nodes and edges, where the underlying random network \(\mathbf A\) is an RDPG random network:
Simulating a sample from an \(RDPG_n(X)\) random network
Choose a latent position matrix, \(X\), whose rows \(\vec x_i\) are the latent positions of the nodes in the network.
For each pair nodes \(i\) and \(j\):
Obtain a weighted coin \((i,j)\) which has a probability of \(\vec x_i^\top \vec x_j\) of landing on heads, and a \(1 - \vec x_i^\top \vec x_j\) probability of landing on tails.
Flip the \((i,j)\) coin, and if it lands on heads, the corresponding entry \(a_{ij}\) in the adjacency matrix is \(1\). If the coin lands on tails, the corresponding entry \(a_{ij} = 0\).
The adjacency matrix you produce, \(A\), is a sample of an \(RDPG_n(X)\) random network.
4.3.3.1. Working out edge probabilities using a latent position matrix#
As you can see above, for the RDPG, you think of the edge probabilities \(p_{ij}\) as a weighted coin, which lands on heads according to the dot product \(\vec x_i^\top \vec x_j\). Let’s explore this in the context of your SBM example from above. Remember that the latent position matrix for your example looked like this:
ax = plot_latent(X, title="Latent Position Matrix", nodetix=[0, 49, 99],
nodelabs=["1", "50", "100"], dimtix=[0.5,1.5], dimlabs=["1", "2"])
plt.show()
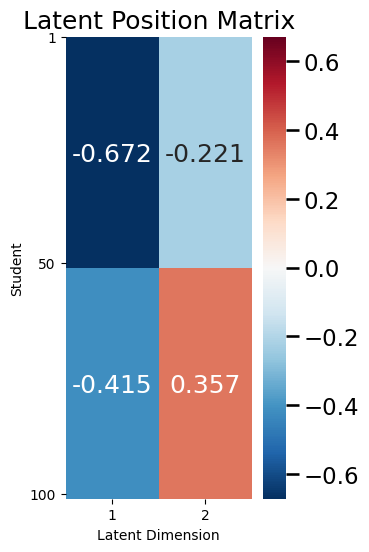
Remember that the first \(50\) students were in school \(1\), and the second \(50\) students were in school \(2\). Looking at the above matrix, you can see that for a student in school \(1\), the latent position vector is:
Then for a pair of students \(i\) and \(j\) who are both in school \(1\) (the community assignments \(z_i\) and \(z_j\) are both \(1\)), the probability they are friends is:
For a student in school \(2\), the latent position vector is:
So for a pair of students \(i\) and \(j\) who are both in school \(2\) (the community assignments \(z_i\) and \(z_j\) are both \(2\)) the probability that they are friends is:
For a pair of students \(i\) and \(j\) whho are in different schools:
This shows that using only the latent position matrix \(X\), you have been able to deduce the corresponding block matrix \(B\), where:
4.3.4. You can do more complicated things with RDPGs than just SBMs#
We will let \(X\) be a little more complex than in our preceding example. Your \(X\) will produce a \(P\) that still somewhat has a modular structure, but not quite as much as before. Let’s assume that you have \(100\) people who live along a very long road that is \(100\) miles long, and each person is \(1\) mile apart. The nodes of your network represent the people who live along your assumed street. The people at the ends of the street host large parties each week, and invite everyone else on the street to their parties. However, if someone lives closer to one party host, they are going to tend to more frequently go to that host’s parties than the other party host. Consequently, when someone lives near a party host, they are going to tend to be better friends with other people who go to that host’s parties more frequently. What could you use for \(X\)?
Remember that the latent positions for each node \(i\) are denoted by the vector \(\vec x_i\). One possible approach would be to let each \(\vec x_i\) be defined as follows:
For instance, \(\vec x_1 = \begin{bmatrix}1 \\ 0\end{bmatrix}\), and \(\vec x_{100} = \begin{bmatrix} 0 \\ 1\end{bmatrix}\). Note that:
What happens in between?
Let’s consider another person, person \(30\). Note that person \(30\) lives closer to person \(1\) than to person \(100\). Here, \(\vec x_{30} = \begin{bmatrix} \frac{7}{10}\\ \frac{3}{10}\end{bmatrix}\). This gives you that:
So this means that person \(1\) and person \(30\) have a \(70\%\) probability of being friends, but person \(30\) and \(100\) have only a \(30\%\) probability of being friends.
Intuitively, it seems like your probability matrix \(P\) will capture the intuitive idea we described above. First, we’ll take a look at \(X\), and then we’ll look at \(P\):
n = 100 # the number of nodes in your network
# design the latent position matrix X according to
# the rules we laid out previously
X = np.zeros((n,2))
for i in range(0, n):
X[i,:] = [(n - i)/n, i/n]
def plot_lp(X, title="", ylab="Student"):
fig, ax = plt.subplots(figsize=(4, 10))
with sns.plotting_context("talk", font_scale=1):
ax = sns.heatmap(X, cmap="Purples",
ax=ax, cbar_kws=dict(shrink=1), yticklabels=False,
xticklabels=False)
ax.set_title(title)
cbar = ax.collections[0].colorbar
ax.set(ylabel=ylab)
ax.set_yticks([0, 29, 69, 99])
ax.set_yticklabels(["1", "30", "70", "100"])
ax.set_xticks([.5, 1.5])
ax.set_xticklabels(["Dimension 1", "Dimension 2"])
cbar.ax.set_frame_on(True)
return
plot_lp(X, title="Latent Position Matrix, X")
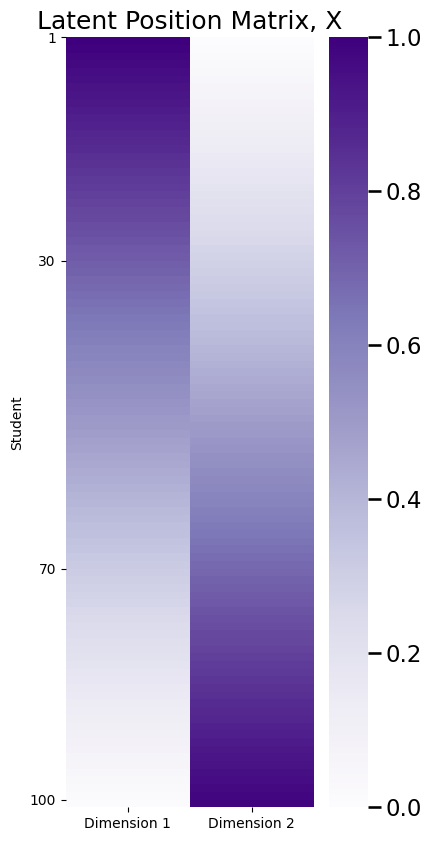
The latent position matrix \(X\) that you plotted above is \(n \times d\) dimensions. There are a number of approaches, other than looking at a heatmap of \(X\), with which you can visualize \(X\) to derive insights as to its structure. When \(d=2\), another popular visualization is to look at the latent positions, \(\vec x_i\), as individual points in \(2\)-dimensional space. This will give you a scatter plot of \(n\) points, each of which has two coordinates. Each point is the latent position for a single node:
def plot_latents(latent_positions, title=None, labels=None, **kwargs):
fig, ax = plt.subplots(figsize=(6, 6))
if ax is None:
ax = plt.gca()
ss = 2*np.arange(0, 50)
plot = sns.scatterplot(x=latent_positions[ss, 0], y=latent_positions[ss, 1], hue=labels,
s=10, ax=ax, palette="Set1", color='k', **kwargs)
ax.set_title(title)
ax.set(ylabel="Dimension 1", xlabel="Dimension 2")
ax.set_title(title)
return plot
# plot
plot_latents(X, title="Latent Position Matrix, X");
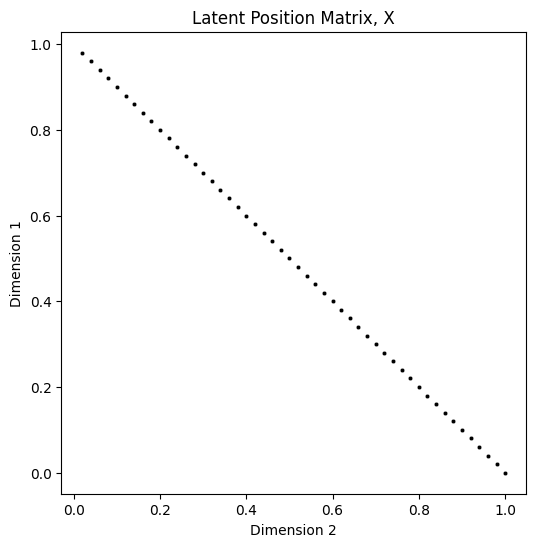
The above scatter plot has been subsampled to show only every \(2^{nd}\) latent position, so that the individual \(2\)-dimensional latent positions are discernable. Due to the way you constructed \(X\), the scatter plot would otherwise appear to be a line (due to points overlapping one another). The reason that the points fall along a vertical line when plotted as a vector is due to the method you used to construct entries of \(X\), described above. Next, you will look at the probability matrix:
plot_prob(X.dot(X.transpose()), title="Probability Matrix, P=$XX^T$",
nodelabs=["1", "30", "70", "100"], nodetix=[0,29,69,99])
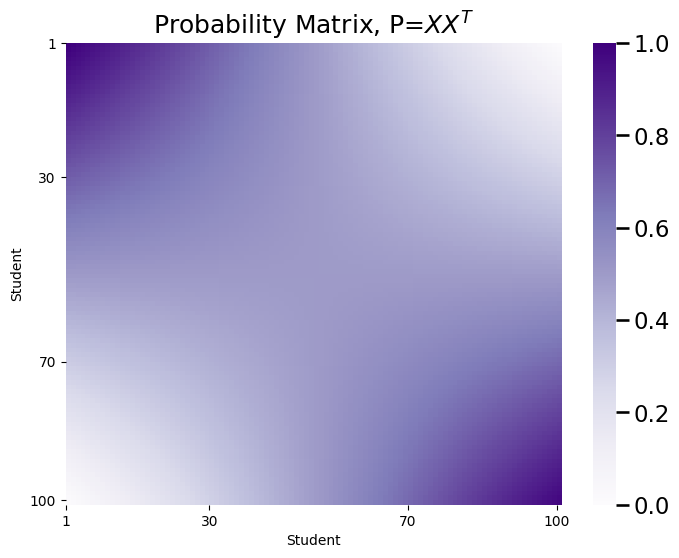
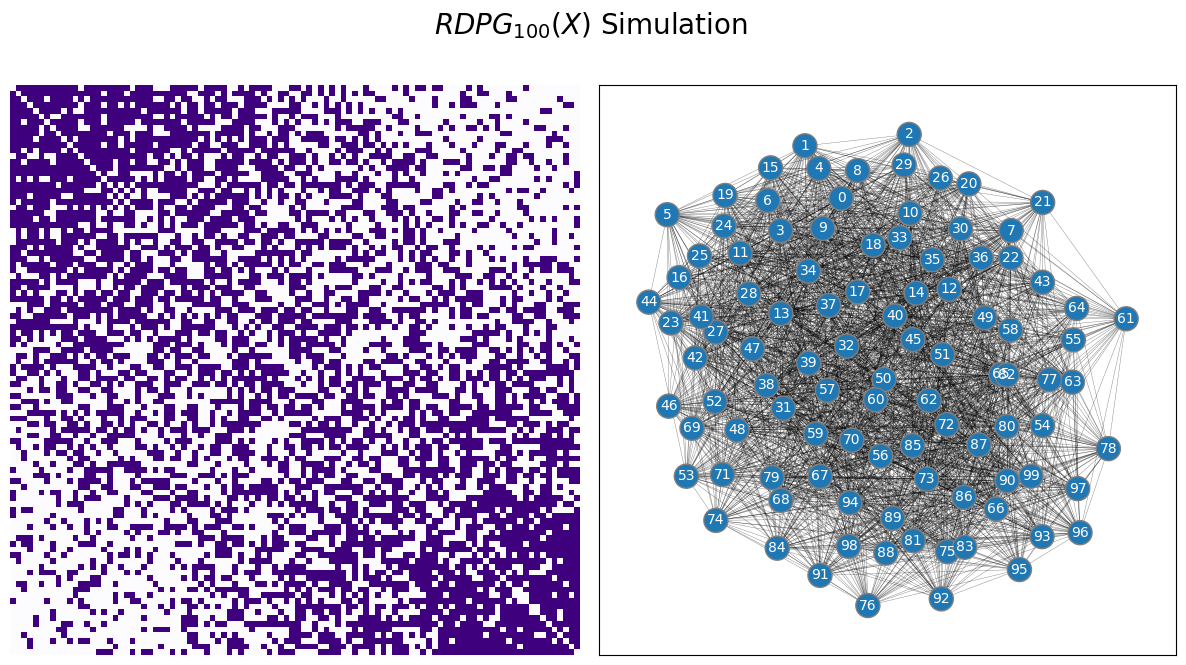
Finally, you will sample an RDPG:
from graspologic.simulations import rdpg
from graphbook_code import draw_multiplot
# sample an RDPG with the latent position matrix
# created above
A = rdpg(X, loops=False, directed=False)
# and plot it
ax = draw_multiplot(A, title="$RDPG_{100}(X)$ Simulation")
4.3.5. RDPGs for more complicated networks#
The RDPG is an excellent model for simple networks. It is flexible, and we can do a wonderful job of deciphering reasonable “guesses” at what the latent position might be given a network sample. This idea will form the basis of Section 5.3, and motivates many of the approaches that we will see later in the applications sections. As it turns out, by changing up the model very slightly, you can even use a variation of the RDPG, called the generalized RDPG (GRDPG) for more complicated networks, too. By adding a second latent position matrix (called the right latent position matrix), which has the same interpretation as the original latent position matrix (now called the left latent position matrix), you can model the probability matrix \(P\) as \(P = XY^\top\). As it turns out, under this formulation, you can represent any random network as a GRDPG.
4.3.6. References#
For more technical depth on the RDPG and more details on the GRDPG, check out the appendix section RDPGs and more general network models, or the excellent survey paper [3].
- 1
Stephen J. Young and Edward R. Scheinerman. Random Dot Product Graph Models for Social Networks. In Algorithms and Models for the Web-Graph, pages 138–149. Springer, Berlin, Germany, 2007. doi:10.1007/978-3-540-77004-6_11.
- 2
Avanti Athreya, Donniell E. Fishkind, Minh Tang, Carey E. Priebe, Youngser Park, Joshua T. Vogelstein, Keith Levin, Vince Lyzinski, and Yichen Qin. Statistical inference on random dot product graphs: a survey. J. Mach. Learn. Res., 18(1):8393–8484, January 2017. doi:10.5555/3122009.3242083.