Applications When You Have One Network
6. Applications When You Have One Network#
Over the last few chapters, we’ve come quite a long way. We’ve learned about network-valued data, and the intricacies of networks that make them unique. We’ve covered ways to conceptualize network-valued data, and how to capture the randomness inherent in network measurements using statistical models. Most recently, you learned a variety of approaches to take your network, and transform the network or collection of networks into a different representation. In this section, we’ll begin to learn why, exactly, we transformed the network(s) into new representations. We’ll cover machine learning systems that we can use, in conjunction with these new representations, to derive insights about our network(s). Further, we’ll learn how to take what we learn about the network, and make general inferences that apply beyond just the particular network measurement we obtained. In this section, we’ll cover how to do this when you have one network.
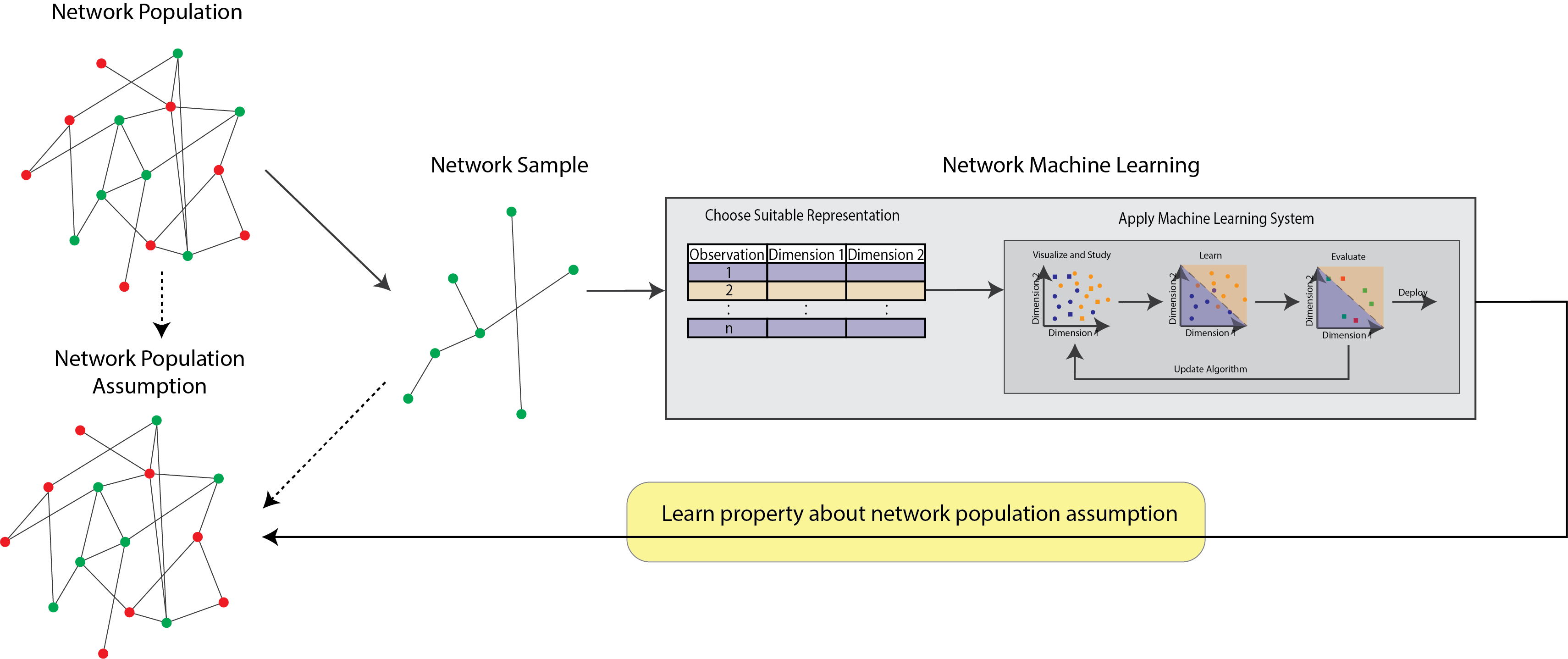
Fig. 6.1 The statistical learning pipeline. In this chapter, you will learn about how to apply network machine learning systems to derive insights about a single network and its representation, and how to apply those insights to make inferences about the underlying network population.#