Spectral Method Theory
Contents
12.2. Spectral Method Theory#
We’ve tried to present this material so far in a manner which is as easy to understand as possible with a distant understanding of probability/statistics and a working knowledge of machine learning. Unfortunately, there is really no way around it now, so this section is about to get hairy mathematically. To understand this section properly, you should have an extremely firm understanding of linear algebra, and more than likely, should have a working knowledge of matrix analysis and multivariate probability theory. While we’ve already seen some concentration inequalities in the last section (Chebyshev’s inequality) you should have a working knowledge of how this term can be extended to random vectors and matrices before proceeding. Before taking on this section, we would recommend checking out the excellent primer [6], which should get you a good foundation to understand many of the results we will take a look at here. We aren’t going to prove many of these results; if you want more details, please check out [3].
Buckle up!
12.2.1. Disclaimer about classical statistical asymptotic theory#
While in classic statistics there is a large literature that derives the large sample properties of an estimator, these concepts are more challenging in network analysis for multiple reasons. To start with, the very basic concept of sample size is not particularly clear. We often associate sample size with the number of observations, which are usually assumed to be independent from each other (for example, think of the number of poll participants to estimate polling preferences). In a network, having independent observations is no longer possible in the same way since all we observe are edges, and they are related to some type of interaction between two vertices. We therefore often assume that the sampled units are the vertices. However, everytime a new node is added, a new set of interactions with all the existing vertices is added to the model, which often results in the need of including more parameters, leading to the second important challenge in studying networks. A body of new literature has addressed some of these challenges for the models and estimators introduced in the previous sections, and we review some of these results here.
12.2.2. Adjacency spectral embedding#
In the following sections, we summarize some of the main results in the literature about spectral embeddings. A more in-deep review of this results is presented in [3] and [7]. In this section, we review some theoretical properties for the adjacency spectral embedding (ASE), introduced in Section 5.3. We focus on contextualizing this method using the random dot product graph (RDPG) model from Section 4.3. If you haven’t, we’d recommend you check out the appendix section as well from Section 11.6.
The results we present in this section aim to understand the general question of how effective the spectral embedding methods are in estimating the latent positions of a random network generated from the RDPG model. Ideally, we would like these embeddings to be as close as possible to the true latent positions. The results we present on this section show that these estimates are indeed close if the network is sufficiently large. Moreover, the limiting distribution of these estimates can be characterized explicitly in a similar fashion as the classic central limit theorems in statistics.
In the rest of the section, we consider a random adjacency matrix \(\mathbf{A}\) with \(n\) vertices sampled from the RDPG model with latent positions \(\mathbf{X}\in\mathbb{R}^{n\times d}\). We write this matrix as \(\mathbf{X}= [\mathbf{x}_1, \ldots, \mathbf{x}_n]^\top\), so that the row \(i\) contains a vector \(\mathbf{x}_i\in\mathbb{R}^d\) which represents the latent position of node \(i\), and as such, the upper-tiangular entries of \(\mathbf{A}\) are independent with probability
The rows of \(\mathbf X\), are assumed to be independent and identically distributed with \(\vec{\mathbf x}_1, \ldots, \vec{\mathbf x}_n\overset{\text{i.i.d.}}{\sim} F\), where \(F\) is a distribution with support in \(\mathbb R^d\). We use \(\widehat{\mathbf X}=ASE(\mathbf A)\in\mathbb R^{n\times d}\) to denote the \(d\)-dimensional adjacency spectral embedding of \(\mathbf A\).
12.2.2.1. Statistical error of the adjacency spectral embedding#
12.2.2.1.1. Consistency#
As we have observed before (for instance, see Section 4.3), the latent position matrix \(\mathbf{X}\) of the network \(\mathbf{A}\) encodes important node properties, such as community assignments, or more generally, a latent geometry that characterizes the probabilites of the edges. As such, it is fundamental to understand how close the true and the estimated latent positions (obtained from the ASE) are from each other. The answer depends on several factors that we review here.
When we want to compare the estimates and the true latent positions, we face a unavoidable problem: the parameters of a random dot product graph, namely, the latent positions, are not identifiable. In other words, given a matrix \(\mathbf{X}\), it is possible to find another matrix \(\mathbf{Y}\in\mathbb{R}^{n \times d}\) that produces exactly the same edge probability matrix, that is, \(\mathbf{P} = \mathbf{X} \mathbf{X}^\top = \mathbf{Y}\mathbf{Y}^\top\). For instance, changing the signs of the columns of \(\mathbf X\) does not change the inner products of their rows, and thus, the matrix \(\mathbf{P}\) remains unaffected to these type of transformations. In general, as long as the columns of \(\mathbf{X}\) are linearly independent, all the possible matrices \(\mathbf{Y}\) that satisfy the previous relation are equal up to an orthogonal transformation. In other words, there exists an orthogonal matrix \(\mathbf{W}\) of size \(d\times d\) such that \(\mathbf{Y} =\mathbf{X}\mathbf{W}\). Here we need to make a technical assumption to guarantee that this condition (that the columns of \(\mathbf{X}\) are linearly independent) holds with high probability. In particular, we will assume that the second moment matrix \(\mathbf{\Delta} = \mathbb{E}[\vec{\mathbf x}_1\vec{\mathbf x}_1^\top]\in\mathbb R^{d\times d}\) has non-zero eigenvalues. This condition simplifies the type of non-identifiabilities we may face, since the probability of having correlated columns in \(\mathbf{X}\) would be very small if \(n\) is sufficiently large.
The first result we review concerns the error of the adjacency spectral embedding (ASE) method; that is, the difference between \(\mathbf{X}\) and the estimated latent position matrix \(\widehat{\mathbf X}\). This estimator has been shown to consistently estimate the latent positions. In other words, as the sample size (number of nodes) increases, the estimated latent positions approach the true latent positions. The typical distance between these two matrices can be quantified explicitly in terms of the sample size \(n\), dimension of the latent positions \(d\) and a constant \(C\) that only depends on the particular distribution of the latent positions \(F\). In particular, with probability tending to one as \(n\) goes to infinity, it holds that the largest distance between the true and estimated latent positions satisfies:
Here, \(\mathbf W\in\mathbb R^{d\times d}\) is an orthogonal matrix (which depends on the specific values of \(\widehat{\mathbf X}\) and \(\mathbf{X}\)) that accounts for the non-identifiability of the latent positions we mentioned before. In other words, this equation shows that the true and estimated latent positions (after a proper orthogonal rotation) are uniformly close to each other, and they get closer as \(n\) grows. We refer to them as uniformly close because the choice of a constant \(C\) holds for all \(n\) nodes. Note that the error rate also depends on the dimension of the model \(d\), since as \(d\) gets larger, the dimension of the parameter space increases and the estimation error also increases.
12.2.2.1.2. Asymptotic normality#
A further result on the asymptotic properties of the ASE concerns to the distribution of the estimation error; that is, the difference between the estimated latent position \(\widehat{\vec{\mathbf x}}_i\) (for a given node \(i\)) and the true parameter \(\vec{\mathbf x}_i\). Because the estimator is consistent, this difference shrinks with \(n\) (after the proper orthogonal rotation), but knowing this fact is not enough if one desires to quantify their difference more carefully. This is important, as some statistical tasks, such as hypothesis testing or confidence interval estimation, require to know distributional properties of the estimation error.
Distributional results on the rows of the adjacency spectral embedding show that the error in estimating the true latent positions converge to a type of multivariate normal normal distribution as the size of the network grows. In particular, it has been shown that the difference between \(\widehat{\mathbf{X}}\) and \(\mathbf{X}\), after a proper orthogonal transformation \(\mathbf{W}_n\), converge to a mixture of multivariate normal distributions. Formally, we can write the multivariate cumulative distribution function for any given vector \(\vec{\mathbf{z}}\in\mathbb R^{d}\) as
where \(\Phi(\cdot, \mathbf{\Sigma}(\vec{\mathbf{x}}))\) is the cumulative distribution function of a \(d\)-dimensional multivariate normal distribution with mean zero and a covariance matrix \(\mathbf{\Sigma}(\vec{\mathbf{x}})\in\mathbb R^{d\times d}\). It is worth noting that the integral on the right hand side operates over all possible values of \(\vec{\mathbf{x}}\in\mathbb{R}^d\), and it is integrated with respect to the distribution of the latent positions, which are sample independently from \(F\). The covariance matrix \(\mathbf{\Sigma}(\vec{\mathbf x})\) depends on a specific value of a latent position \(\vec{\mathbf x}\in\mathbb{R}^d\), and is given by:
For certain classes of distributions, it is possible to simplify this expression further to get a more specific form of the asymptotic distribution of \(\widehat{\vec{\mathbf x}}_i\). We present an example later on this section.
The two results presented on this section constitute the basic properties of the adjacency spectral embedding under the RDPG model, but existing results are not limited to this particular method and model. Extensions of these results to a broader class of network models have been already developed (included the so-called generalized random dot product graphs). Analogous results also exist for other type of embedding methodologies. For instance, the Laplacian spectral embedding (LSE, from Section 5.3) possess analogous properties to the ASE (namely, consistent estimates with known asymptotic distribution), although the particular form of this theorem is a bit more complicated. The study of different network models and embedding methods is still a research area under development, and new results keep coming every day.
12.2.2.2. Example: Erdős-Rényi graphs and the adjacency spectral embedding#
The ER model (from Section 4.1 and Section 11.4) is the simplest example of a Random Dot Product Graph, in which all edge probabilities are the same. We will use this model to derive concrete expressions for the equations in the theory we have presented. Suppose that \(\mathbf A\) is a random network with a \(ER_n(p)\) distribution, for some \(p\in(0,1)\). We can write the distribution of this network using a unidimensional latent position matrix \(\vec{\mathbf x} = (\mathbf x_1, \ldots, \mathbf x_n)^\top\), with all entries equal to \(\sqrt{p}\), since this will give
Thus, the ER graph \(ER_n(p)\) can be thought as a RDPG with distribution of the latent positions \(F=\delta_{\sqrt{p}}\), where \(\delta_{\sqrt{p}}\) is the Dirac delta distribution that only assigns positive probability to the mass point \(\sqrt{p}\). It is worth noting that from this representation we can already notice a non-identifiability in the model, as both \(\vec{\mathbf x}\) and \(-\vec{\mathbf x}\) will result in the same edge probabilities. For practical purposes, it does not matter which of these two representations we recover.
The adjacency spectral embedding of the ER graph \(\mathbf{A}\) is the unidimensional vector \(\widehat{\vec{\mathbf x}} = \widehat{\lambda}\widehat{\vec{\mathbf v}}\), where \(\widehat{\vec{\mathbf v}}\in\mathbb{R}^n\) and \(\widehat{\lambda}\in\mathbb{R}\) are the leading eigenvector and eigenvalue of \(\mathbf{A}\). The adjacency spectral embedding of \(\mathbf{A}\) is simply given by \(\widehat{\vec{\mathbf x}} = ASE(\mathbf{A}) = \sqrt{\widehat{\lambda}}\widehat{\vec{\mathbf v}}\). According to the theory presented before, we have that the error in estimating \(\vec{\mathbf{x}}\) from \(\widehat{\vec{\mathbf{x}}}\) should decrease as the size of the network increases. In particular, we have that:
Here, \(w_n\) plays the role of a one-dimensional orthogonal matrix that accounts for the non-identifiability of the model; in other words, \(w_n\) is either equal to \(1\) or \(-1\), which comes from the sign ambiguity of the singular vectors. Let’s see how this works out in practice. We’ll begin by simulating \(50\) networks as-specified above, for networks with increasing numbers of nodes from around \(30\) to around \(3000\):
from graspologic.simulations import er_np
import numpy as np
# set the probability ahead of time
p = 0.5
ns = np.round(10**np.linspace(1.5, 3.5, 5)).astype(int)
# run the simulations for each number of nodes
As = [[er_np(n, p) for i in range(0, 50)] for n in ns]
Next, we spectrally embed each network into a single dimension, and then check to make sure the signs of the estimated latent positions and the true latent positions align due to the orthogonality issue:
from graspologic.embed import AdjacencySpectralEmbed as ASE
# instantiate an ASE instance with 1 embedding dimension
ase = ASE(n_components=1)
# check for sign alignment, and flip the signs if Xhat and X disagree
def orthogonal_align(Xhat, p=0.5):
if ((Xhat*np.sqrt(p)).sum() < 0):
Xhat = -Xhat
return Xhat
# compute the estimated latent positions and realign in one step
Xhats_aligned = [[orthogonal_align(ase.fit_transform(A)) for A in An] for An in As]
Finally, we compute the maximum difference between the estimated latent positions (after alignment) and \(\sqrt{p}\) for each network. We divide by \(\log^2(n)\) and multiply by \(\sqrt{n}\), and then plot the result as the average (solid line) and \(95\%\) probability interval (shaded ribbon) for a given value of \(n\). If there exists a constant value \(C\) where as \(n\) grows the values are consistently under this constant with increasing probability, we have demonstrated the desired result empirically:
import pandas as pd
import seaborn as sns
network_numbers = np.vstack([np.vstack([np.full((n, 1), i) for i in range(0, 50)]) for n in ns]).flatten()
node_indices = np.vstack([np.vstack([np.arange(0, n).reshape((n, 1)) for i in range(0, 50)]) for n in ns]).flatten()
node_counts = np.vstack([np.vstack([np.full((n, 1), n) for i in range(0, 50)]) for n in ns]).flatten()
Xhats_aligned_flat = np.vstack([np.vstack([Xhat for Xhat in Xhats_n]) for Xhats_n in Xhats_aligned]).flatten()
df = pd.DataFrame({"Xhat": Xhats_aligned_flat, "i" : node_indices, "n" : node_counts,
"j" : network_numbers, "X" : np.sqrt(p)})
df["abs_diff"] = np.abs(df["Xhat"] - df["X"])
max_pernet = df.groupby(
["n", "j"]
).agg({
"abs_diff": "max"
}).reset_index()
max_pernet["norm_factor"] = np.log(max_pernet["n"])**2/np.sqrt(max_pernet["n"])
max_pernet["norm_diff"] = max_pernet["abs_diff"]/max_pernet["norm_factor"]
ax = sns.lineplot(data=max_pernet, x="n", y="norm_diff")
ax.set_xlabel("Number of Nodes")
ax.set_ylabel("$ \\frac{\\sqrt{n}\,\, max_i |\hat x_i - \sqrt{p} w_n|}{\log^2(n)}$");
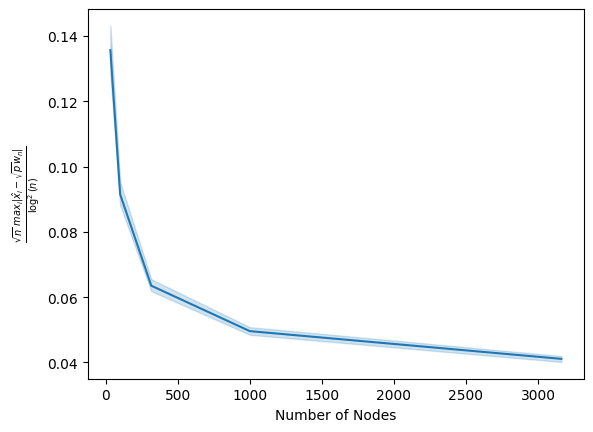
As we can see, this value drops off pretty rapidly as we increase the number of nodes. Therefore, we could choose basically any constant attained by this curve (such as, for instance, \(0.10\)), and the above plot demonstrates that empirically, as the number of nodes approaches infinity, the probability that the \(y\)-axis values are less than our choice of a constant tends towards \(1\), as desired. Pretty neat, right?
Similarly, we can also obtain an expression for the asymptotic distribution of the difference between the true and estimated positions. First, notice that since \(F\) has only one point mass at \(\sqrt{p}\), we can evaluate integrals and expections with respect to this distribution, resulting in
The exact form of the covariance term \(\mathbf{\Sigma}(\mathbf{x})\) can be obtained from the second moment matrix \(\mathbf{\Delta} = \mathbb{E}[\mathbf{x}_1^2] = p\), and it is given by:
Combining these results, we get that the limiting distribution of the difference between \(\widehat{\mathbf{x}}\) and \(\mathbf{x}\) satisfies
The asymptotic normality result is illustrated in the simulation setting below. In particular, observe that, as the size of the network \(n\) increases, the distribution of the entries of \(\mathbf{x}\) resembles the normal distribution. We’ll repeat this for one network from each number of nodes to see this result, by showing a histogram of the limiting factors \(\sqrt{n}(\hat x_i - \sqrt{p})\) in our realized networks for all \(n\) nodes. We will plot it against the pdf for an appropriate normal distribution with mean \(0\) and standard deviation \(1 - p\) in red:
df_reduced = df[df["j"] == 0] # check what happens for the first network from each set
df_reduced = df_reduced.copy()
# isolate the factor sqrt(n)*(xhat_i - sqrt(p)) that we want the limiting distribution of
df_reduced["limiting_factor"] = df_reduced.apply(lambda x: np.sqrt(x.n) *(x.Xhat - x.X), axis=1)
# np.sqrt(df_reduced["n"]) * (df_reduced["Xhat"] - df_reduced["X"])
from scipy.stats import norm
g = sns.FacetGrid(df_reduced, col="n")
g.map(sns.histplot, "limiting_factor", stat="density")
truth = pd.DataFrame({"x" : np.linspace(-2, 2, 100)})
truth["y"] = norm.pdf(truth["x"], scale=np.sqrt(1-p))
axes = g.fig.axes
for ax in axes:
sns.lineplot(data=truth, x="x", y="y", ax=ax, color="red");
g.set_axis_labels("$\\sqrt{n}(\\hat x_i - \sqrt{p})$");
/opt/hostedtoolcache/Python/3.8.16/x64/lib/python3.8/site-packages/seaborn/axisgrid.py:703: FutureWarning: iteritems is deprecated and will be removed in a future version. Use .items instead.
plot_args = [v for k, v in plot_data.iteritems()]
/opt/hostedtoolcache/Python/3.8.16/x64/lib/python3.8/site-packages/seaborn/axisgrid.py:703: FutureWarning: iteritems is deprecated and will be removed in a future version. Use .items instead.
plot_args = [v for k, v in plot_data.iteritems()]
/opt/hostedtoolcache/Python/3.8.16/x64/lib/python3.8/site-packages/seaborn/axisgrid.py:703: FutureWarning: iteritems is deprecated and will be removed in a future version. Use .items instead.
plot_args = [v for k, v in plot_data.iteritems()]
/opt/hostedtoolcache/Python/3.8.16/x64/lib/python3.8/site-packages/seaborn/axisgrid.py:703: FutureWarning: iteritems is deprecated and will be removed in a future version. Use .items instead.
plot_args = [v for k, v in plot_data.iteritems()]
/opt/hostedtoolcache/Python/3.8.16/x64/lib/python3.8/site-packages/seaborn/axisgrid.py:703: FutureWarning: iteritems is deprecated and will be removed in a future version. Use .items instead.
plot_args = [v for k, v in plot_data.iteritems()]

As \(n\) grows, the limiting distribution of \(\sqrt n(\hat x_i - \sqrt{p})\) clearly approaches the desired normal distribution.
12.2.2.3. Application: two-graph hypothesis testing#
The results previously discussed demonstrate that the true and estimated latent positions are close to each other, and in fact, their distance gets smaller as \(n\) increases. As such, the ASE provides an accurate estimator of the latent positions. This result justifies the use of \(\mathbf {\hat X}\) in place of \(\mathbf X\) for subsequent inference tasks, such as community detection, vertex nomination, or classification (see Sections Section 6.1, Section 6.4, or Section 7.3 for a more thorough discussion on these topics). The theoretical results for the ASE have multiple implications. One of those is that the estimated latent positions carry almost the same information as the true latent positions, and we can even quantify how different they are. This is particularly useful for performing statistical inference tasks about node properties. Here we consider one of these tasks: two-graph hypothesis testing [2].
Comparing the distribution of two populations is a frequent problem in statistics and across multiple domains. In classical statistics, a typical strategy to perform this task is to compare the mean of two populations by using an appropriate test statistic. Theoretical results on the distribution of this statistic (either exact or asymptotic) are then used to derive a measure of uncertainty for this problem (such as p-values or confidence intervals). Similarly, when comparing two observed graphs, we may wonder whether they were generated by the same mechanism. The results discussed before have been used to develop valid statistical tests for two-network hypothesis testing questions.
A network hypothesis test for the equivalence between the latent positions of the vertices of a pair of networks with aligned vertices can be constructed by using the estimates of the latent positions. Formally, let \(X, Y\) be the latent position matrices, and define \(\mathbf A\sim RDPG(X)\), \(\mathbf B\sim RDPG(Y)\) as independent random adjacency matrices. We can test whether the two networks have the same distribution by comparing their latent positions via a hypothesis test of the form
where \(\mathbf X =_{W}Y\) denotes that \(X\) and \(Y\) are equivalent up to an orthogonal transformation \(W\in\mathcal{O}_d\), and \(\mathcal{O}_d\) is the set of \(d\times d\) orthogonal matrices. Since we do not have access to the true latent positions, we can use the estimates \(\widehat{X}\) and \(\widehat{Y}\) to construct a test statsistic. This test statistic is defined as
Here, \(\|\widehat{X}W - \widehat{Y}\|_F\) is the Frobenius distance between the estimated latent positions (after adjusting for the orthogonal non-identifiability). This distance compares how similar the two latent positions are, and thus, it is natural to think that larger values of this distance will give more evidence agains the null hypothesis. In addition to this, the test statistic incorporates a normalizing constant of the form \(\sqrt{d\gamma^{-1}(\mathbf A)} + \sqrt{d\gamma^{-1}(\mathbf B)}\). Here \(\sigma_1(\mathbf A) \geq \ldots\geq \sigma_n(\mathbf A)\geq 0\) denote the singular values of \(\mathbf A\) (similarly for \(\mathbf B\)), \(\delta(\mathbf A) = \max_{i\in[n]}\sum_{j=1}^n\mathbf A_{ij}\) denotes the largest observed degree of the graph, and
is a constant that standardizes the test statistic. It can be shown that, under appropriate regularity conditions that this test statistic will go to zero as \(n\) goes to infinity under the null hypothesis, and will diverge with \(n\) for some specific alternatives. Thus, \(\mathbf t\) provides a way to construct a consistent test for the hypothesis testing problem described above.
12.2.3. Theory for multiple network models#
Models for multiple network data often assume that there is a known one-to-one correspondence between the vertices of the graphs. If this correspondence is unknown, an estimate can be obtained via graph matching, which you learned about in Section 7.3. Once the vertices are correctly matched, models for multiple networks exploit the shared structure across the graphs to obtain accurate estimates. In this section we review the theoretical challenges on these circumstances. You can learn more about the problem space across a bevy of excellent academic survey papers such as [8], [9], or [10] for more details.
12.2.3.2. Joint spectral embeddings#
12.2.3.3. Omnibus Embedding (omni)#
The omnibus embedding described in Section 5.4 jointly estimates the latent positions under the joint random dot product network (\(JRDPG\)) model, which is discussed in Section 4.7. Briefly, the model is \((\mathbf A^{(1)}, \ldots, \mathbf A^{(m)})\sim JRDPG(\mathbf X_n)\), and the rows of \(\mathbf X_n\in\mathbb R^{n\times d}\) are an i.i.d. sample from some distribution \(F\). Let \(\widehat{\mathbf{O}}\in\mathbb R^{mn\times mn}\) be the omnibus embedding of \(\mathbf A^{(1)}, \ldots, \mathbf A^{(m)}\) and \(\widehat{\mathbf Z} = ASE(\mathbf{O})\in\mathbb R^{mn\times d}\). Under this setting, it can be shown that the rows of \(\widehat{\mathbf Z}_n\) are a consistent estimator of the latent positions of each individual network as \(n\rightarrow\infty\), and that:
Furthermore, a central limit theorem for the rows of the omnibus embedding asserts that:
for some covariance matrix \(\widehat{\Sigma}(\mathbf{x})\). For more details, check out the original paper at [2].
12.2.3.4. Multiple adjacency spectral embedding (MASE)#
The \(COSIE\) model described in Section 4.7 gives a joint model that characterizes the distribution of multiple networks with expected probability matrices that share the same common invariant subspace. The \(MASE\) algorithm in Section 5.4 is a consistent estimator for this common invariant subspace, and results in asymptotically normally estimators for the individual symmetric matrices. Specifically, let \(\mathbf V_n\in\mathbb R^{n\times d}\) be a sequence of orthonormal matrices and \(\mathbf R^{(1)}_n, \ldots, \mathbf R^{(m)}_n\in\mathbb R^{d\times d}\) a sequence of score matrices such that \(\mathbf{P}^{(l)}_n=\mathbf V_n\mathbf R^{(l)}_n\mathbf V_n^\top\in[0,1]^{n\times n} \), \((\mathbf A_n^{(1)}, \ldots, \mathbf A_n^{(m)})\sim COSIE(\mathbf V_n;, \mathbf R^{(1)}_n, \ldots, \mathbf R^{(m)}_n)\), and \(\widehat{\mathbf V}, \widehat{\mathbf R}^{(1)}_n, \ldots, \widehat{\mathbf R}^{(1)}_n\) be the estimators obtained by \(MASE\). Under appropriate regularity conditions, the estimate for \(\mathbf V\) is consistent as \(n,m\rightarrow\infty\), and there exists some constant \(C>0\) such that:
In addition, the entries of \(\widehat{\mathbf{R}}^{(l)}_n\), \(l\in[m]\) are asymptotically normally distributed. Namely, there exists a sequence of orthogonal matrices \(\mathbf W\) such that:
as \(n\rightarrow\infty\), where: \(\mathbb{E}[\|\mathbf H_m^{(l)}\|]=O\left(\frac{d}{\sqrt{m}}\right)\) and \(\sigma^2_{l,j,k} = O(1)\). For more details about the \(MASE\) algorithm, check out [3].
12.2.4. References#
- 1(1,2)
Avanti Athreya, Donniell E. Fishkind, Minh Tang, Carey E. Priebe, Youngser Park, Joshua T. Vogelstein, Keith Levin, Vince Lyzinski, and Yichen Qin. Statistical inference on random dot product graphs: a survey. J. Mach. Learn. Res., 18(1):8393–8484, January 2017. doi:10.5555/3122009.3242083.
- 2
Keith Levin, A. Athreya, M. Tang, V. Lyzinski, and C. Priebe. A Central Limit Theorem for an Omnibus Embedding of Multiple Random Dot Product Graphs. 2017 IEEE International Conference on Data Mining Workshops (ICDMW), 2017. URL: https://www.semanticscholar.org/paper/A-Central-Limit-Theorem-for-an-Omnibus-Embedding-of-Levin-Athreya/fdc658ee1a25c511d7da405a9df7b30b613e8dc8.
- 3
Jesús Arroyo, Avanti Athreya, Joshua Cape, Guodong Chen, Carey E. Priebe, and Joshua T. Vogelstein. Inference for Multiple Heterogeneous Networks with a Common Invariant Subspace. Journal of Machine Learning Research, 22(142):1–49, 2021. URL: https://jmlr.org/papers/v22/19-558.html.
- 4
Vince Lyzinski, Donniell E. Fishkind, and Carey E. Priebe. Seeded graph matching for correlated Erdös-Rényi graphs. J. Mach. Learn. Res., 15(1):3513–3540, January 2014. doi:10.5555/2627435.2750357.
- 5
Minh Tang, Avanti Athreya, Daniel L. Sussman, Vince Lyzinski, Youngser Park, and Carey E. Priebe. A Semiparametric Two-Sample Hypothesis Testing Problem for Random Graphs. J. Comput. Graph. Stat., 26(2):344–354, April 2017. doi:10.1080/10618600.2016.1193505.
- 6
Roman Vershynin. High-Dimensional Probability: An Introduction with Applications in Data Science. Cambridge University Press, Cambridge, England, UK, September 2018. ISBN 978-1-10823159-6. doi:10.1017/9781108231596.
- 7
Daniel L. Sussman, Minh Tang, Donniell E. Fishkind, and Carey E. Priebe. A Consistent Adjacency Spectral Embedding for Stochastic Blockmodel Graphs. J. Am. Stat. Assoc., 107(499):1119–1128, September 2012. doi:10.1080/01621459.2012.699795.
- 8
D. Conte, P. Foggia, C. Sansone, and M. Vento. THIRTY YEARS OF GRAPH MATCHING IN PATTERN RECOGNITION. Int. J. Pattern Recognit. Artif. Intell., 18(03):265–298, May 2004. doi:10.1142/S0218001404003228.
- 9
Pasquale Foggia, Gennaro Percannella, and Mario Vento. GRAPH MATCHING AND LEARNING IN PATTERN RECOGNITION IN THE LAST 10 YEARS. Int. J. Pattern Recognit. Artif. Intell., 28(01):1450001, October 2013. doi:10.1142/S0218001414500013.
- 10
Junchi Yan, Xu-Cheng Yin, Weiyao Lin, Cheng Deng, Hongyuan Zha, and Xiaokang Yang. A Short Survey of Recent Advances in Graph Matching. In ICMR '16: Proceedings of the 2016 ACM on International Conference on Multimedia Retrieval, pages 167–174. Association for Computing Machinery, New York, NY, USA, June 2016. doi:10.1145/2911996.2912035.