Exploratory analysis on volume correlations#
Show code cell content
from itertools import combinations, combinations_with_replacement
import graspologic as gp
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from matplotlib.patches import RegularPolygon
from matplotlib.transforms import Bbox
from scipy.stats import kruskal, mannwhitneyu, rankdata, wilcoxon
from seaborn.utils import relative_luminance
from statsmodels.stats.multitest import multipletests
import hyppo
from hyppo.ksample import MANOVA, KSample
from pkg.data import (
GENOTYPES,
HEMISPHERES,
SUB_STRUCTURES,
SUPER_STRUCTURES,
load_fa_corr,
load_vertex_df,
load_vertex_metadata,
load_volume_corr,
)
from pkg.inference import run_ksample, run_pairwise
from pkg.plot import plot_heatmaps, plot_pairwise
from pkg.utils import rank, squareize
matplotlib.rcParams["font.family"] = "monospace"
Plot the data#
# Load the data
volume_correlations, labels = load_volume_corr()
meta = load_vertex_df()
volume_correlations = np.array([rank(v) for v in np.abs(volume_correlations)])
Show code cell source
## Plot to make sure nothing is wrong
fig, ax = plt.subplots(1, 3, figsize=(6, 2), dpi=300)
for idx, label in enumerate(labels):
sns.heatmap(
volume_correlations[idx],
ax=ax[idx],
cbar=False,
cmap="RdBu_r",
xticklabels=False,
yticklabels=False,
center=0,
square=True,
)
ax[idx].set(title=label)

Vectorize matrix and compute kruskal-wallis#
We use KW test for speed since computing large distance distance matrices can be difficult to compute.
# use kruskal-wallis for speed
idx = np.triu_indices_from(volume_correlations[0], k=1)
kruskal(*[c[idx] for c in volume_correlations])
KruskalResult(statistic=0.0, pvalue=1.0)
Try apriori community#
vertex_hemispheres = meta.Hemisphere.values
vertex_structures = meta.Level_1.values
vertex_hemisphere_structures = (meta.Hemisphere + "-" + meta.Level_1).values
vertex_hemisphere_substructures = (meta.Hemisphere + "-" + meta.Level_1 + "-" + meta.Level_2).values
volume_ksample = [
run_ksample(volume_correlations, labels, idx, test="kruskal", absolute=True)
for idx, labels in enumerate(
[
vertex_hemispheres,
vertex_structures,
vertex_hemisphere_structures,
vertex_hemisphere_substructures,
]
)
]
volume_ksample = pd.concat(volume_ksample, ignore_index=True)
volume_ksample.to_csv(
"../results/outputs/ranked_volume_correlation_3sample_apriori.csv", index=False
)
sns.set_context("talk", font_scale=0.5)
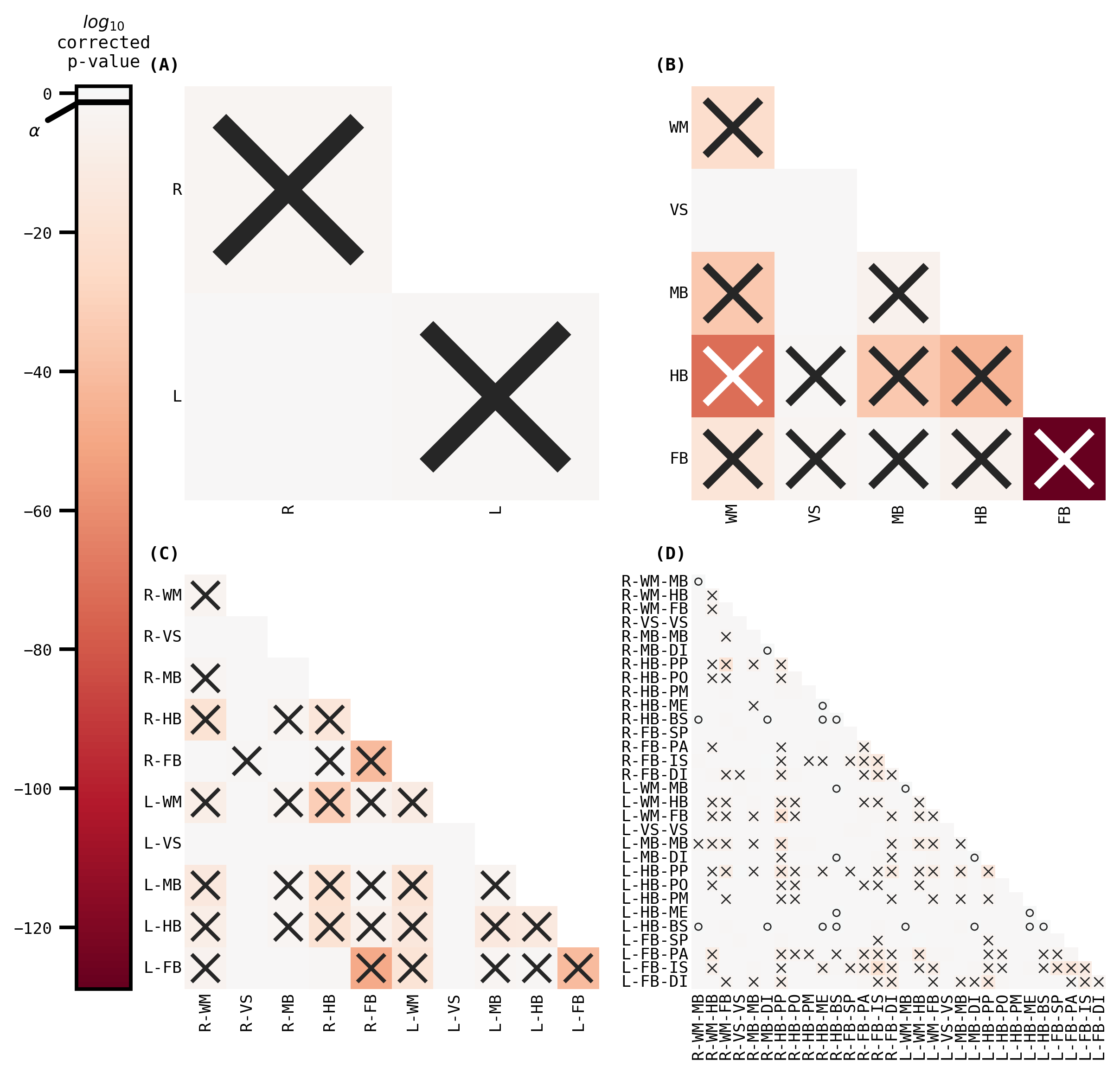
fig, _ = plot_heatmaps(volume_ksample, cbar=True)
fig.savefig("./figures/apriori_ksample_ranked_volume.pdf")
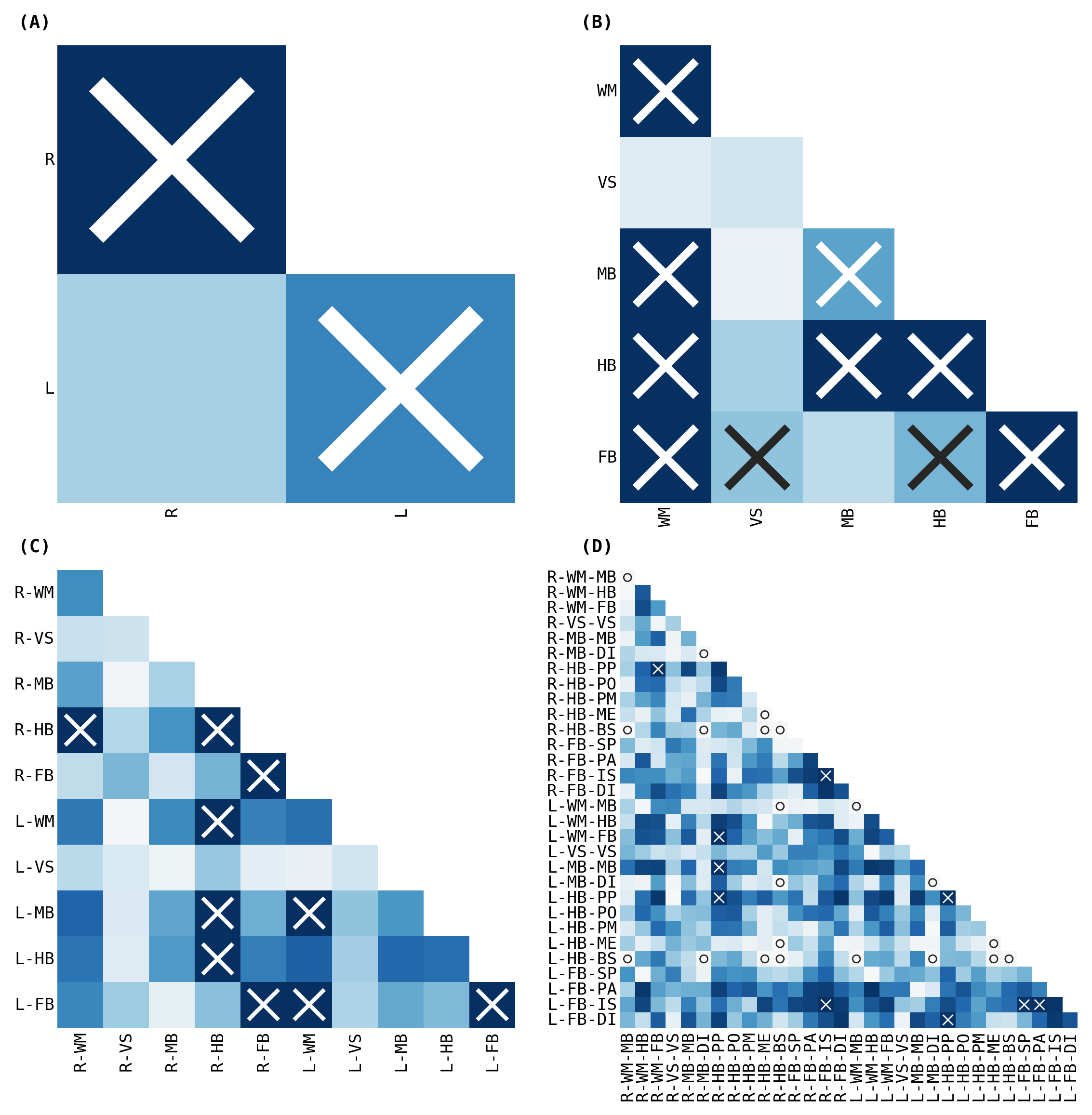
fig, _ = plot_heatmaps(volume_ksample, cbar=False, ranked_pvalue=True)
fig.savefig("./figures/apriori_ksample_ranked_volume_ranked_pval.pdf")
Do FA#
fa_correlations, labels = load_fa_corr()
fa_correlations = np.array([rank(v) for v in np.abs(fa_correlations)])
fa_ksample = [
run_ksample(fa_correlations, labels, idx, test="manova", absolute=True)
for idx, labels in enumerate(
[
vertex_hemispheres,
vertex_structures,
vertex_hemisphere_structures,
vertex_hemisphere_substructures,
]
)
]
fa_ksample = pd.concat(fa_ksample, ignore_index=True)
fa_ksample.to_csv("../results/outputs/ranked_fa_correlation_3sample_apriori.csv", index=False)
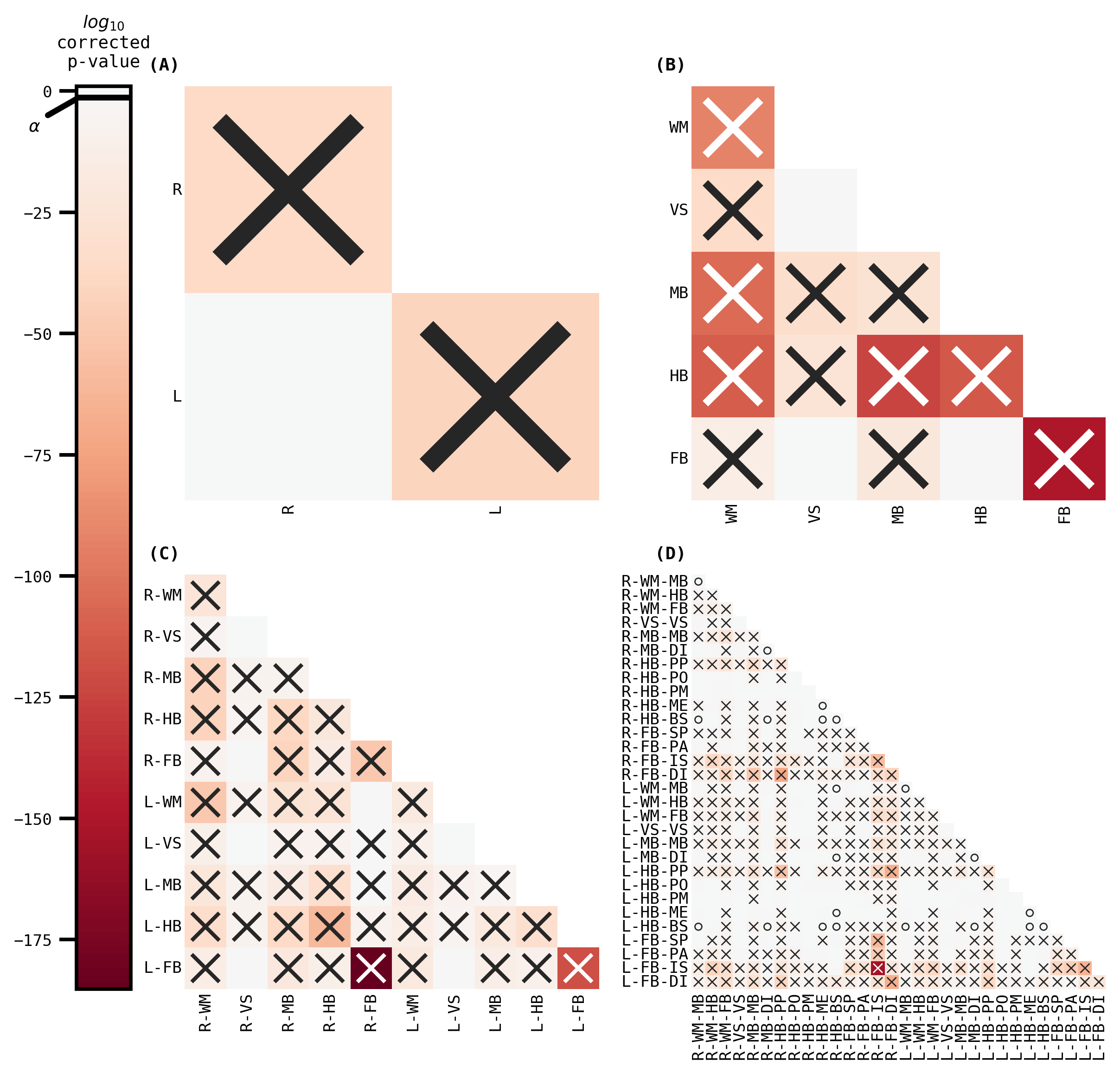
fig, _ = plot_heatmaps(fa_ksample, cbar=True)
fig.savefig("./figures/apriori_ksample_ranked_fa.pdf")
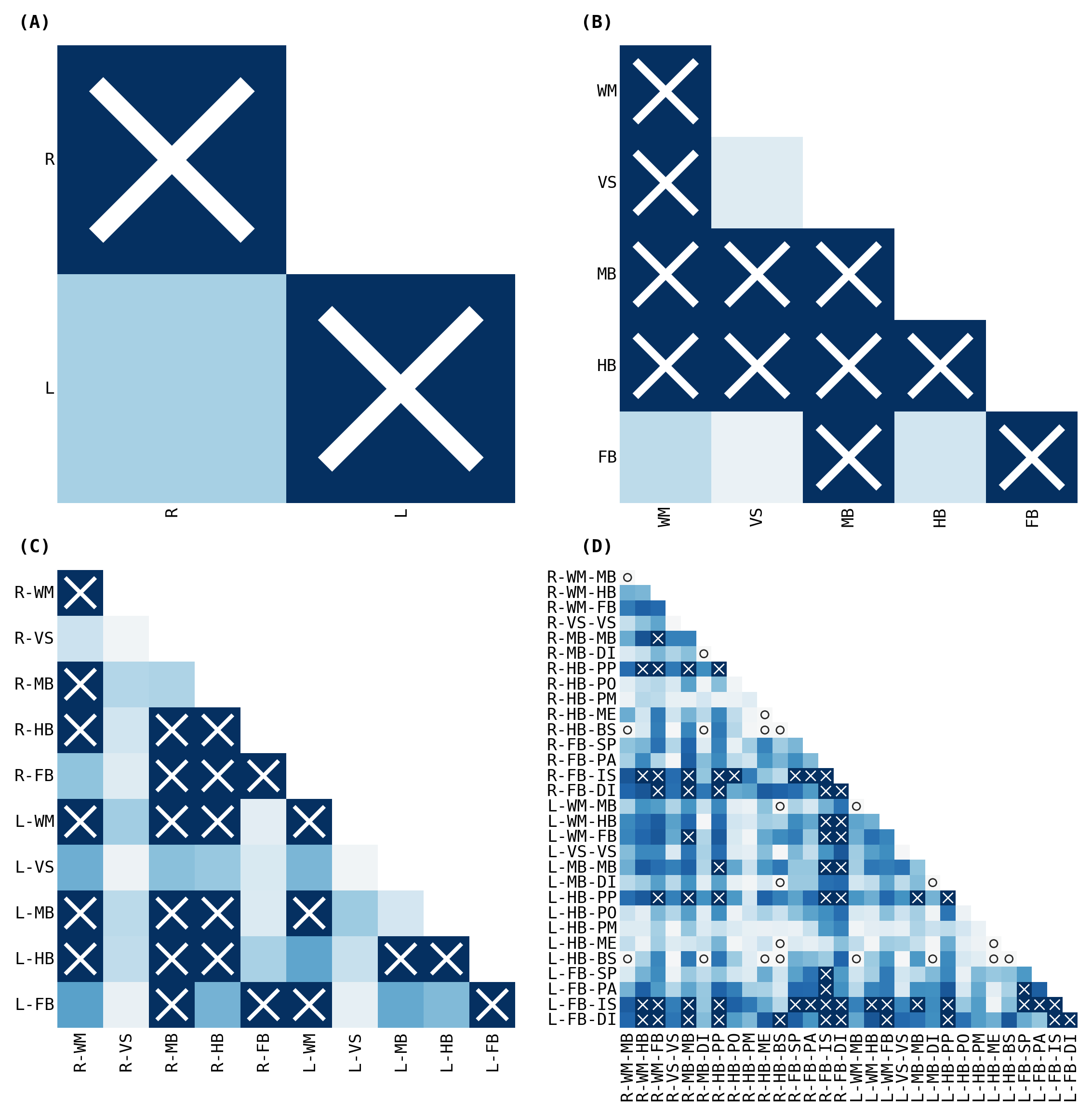
fig, _ = plot_heatmaps(fa_ksample, cbar=False, ranked_pvalue=True)
fig.savefig("./figures/apriori_ksample_ranked_fa_ranked_pval.pdf")
Statistical Experiment#
For a given pair of sub-regions (Left/Right Forebrain, Midbrain, Hindbrain, White Matter Tracts) \(k\) and \(l\), do the edges incident nodes between a pair of sub-regions have the same, or a different, distribution? Formally, consider the following model. Let \(a_{ij}^{(y)}\) be the edge-weight for edge \(i, j\), and let \(z_i \in [K]\) be the node label for node \(i\), where \(y \in \{APOE22, APOE33, APOE44\}\) is the class of the network:
where \(F^{(y)}_{k,l}\) is the distribution function for the community of edges \(k\) and \(l\) in a network of class \(y\). For a given tuple of node communities \((k,l)\) and \((k',l')\), the hypothesis of interest is:
The interpretation of a \(p\)-value less than the cutoff threshold \(\alpha = 0.05\) (after Bonferroni-Holm adjustment) for a given pair of classes \((y, y')\) at a given community pair \((k, l)\) is that the data does not support the null hypothesis, that the community pairing shares an equal distribution between the indicated pair of classes. A sufficient test for this context (univariate data, assumed to be independent, paired) is the Wilcoxon Signed-Rank Test, which can be performed using scipy.
The outcomes (p-values) can be visualized as pairs of heatmaps between a given pair of classes. Further, since the edges are undirected, we can ignore the off-diagonals of the matrix. These outcomes are then ranked, where a large rank indicates the smaller p-values.
volume_pairwise = run_pairwise(
volume_correlations,
GENOTYPES,
vertex_hemisphere_substructures,
absolute=False,
test="mannwhitney",
)
fig, _ = plot_pairwise(volume_pairwise, volume_ksample)
fig.savefig("./figures/apriori_pairwise_ranked_volume.pdf")
fa_pairwise = run_pairwise(
fa_correlations,
GENOTYPES,
vertex_hemisphere_substructures,
absolute=False,
test="mannwhitney",
)
fig, _ = plot_pairwise(fa_pairwise, fa_ksample)
fig.savefig("./figures/apriori_pairwise_ranked_fa.pdf")