Generate Upsetplots
Generate Upsetplots#
In this notebook we will be generating two upsetplots: the first will plot counts of cells based on if they have an entry for the associated annotations, and the second will plot counts of cells based on their values for the associated annotations.
import logging
import pandas as pd
import numpy as np
from itertools import chain, combinations
from upsetplot import plot
from matplotlib import pyplot as plt
from pkg.platy import _get_folder, load_connectome_normal_lcc_annotations
We import the folder to save our upsetplots and the table of annotations which will help us make our upsetplots
folder = _get_folder()
annotations = load_connectome_normal_lcc_annotations()
annotations.fillna("N/A", inplace=True)
annotations
| skids | side | class | segment | type | group | |
|---|---|---|---|---|---|---|
| 0 | 2015233 | l | s | head | 100.0 | N/A |
| 1 | 1548290 | l | N/A | 1 | N/A | N/A |
| 2 | 1318919 | l | s | head | 88.0 | 15.0 |
| 3 | 2015241 | l | s | head | 100.0 | N/A |
| 4 | 1646603 | r | N/A | 3 | N/A | N/A |
| ... | ... | ... | ... | ... | ... | ... |
| 2696 | 1302513 | l | s | head | N/A | N/A |
| 2697 | 1630186 | l | N/A | 2 | N/A | N/A |
| 2698 | 1441779 | r | N/A | head | N/A | N/A |
| 2699 | 1671147 | r | m | 1 | 165.0 | N/A |
| 2700 | 1048573 | l | i | 3 | N/A | N/A |
2701 rows × 6 columns
The following function returns a series where the indices are all the skids in the annotations table and the values are if they have a value for the category passed in
#returns boolean pandas series: False if element is "N/A", else True
def has_category(annotations, category="side"):
has_list = []
series_name = "has_{}".format(category)
for val in annotations[category]:
if val != "N/A":
has_list.append(True)
else:
has_list.append(False)
return pd.Series(index=annotations["skids"], data=has_list, name=series_name)
#generate boolean pandas series for the different categories
has_categs = {"has_side": None, "has_class": None, "has_segment": None, "has_type": None, "has_group": None}
for key in has_categs:
has_categs[key] = has_category(annotations, category=key.split("_")[1])
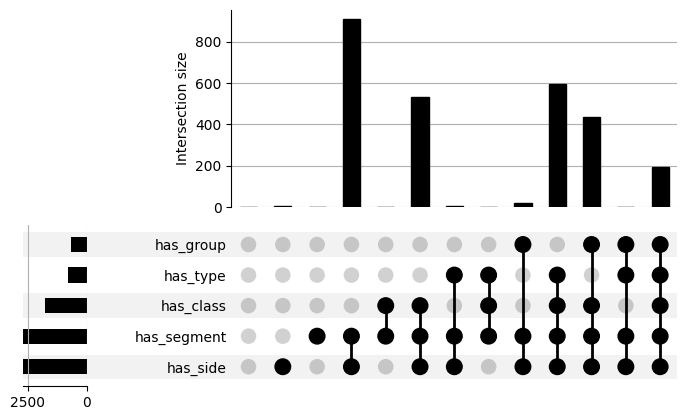
With series of booleans for all our categories, we can concatenate our series to make a dataframe, and call groupby which will group the dataframe based on the number of cells for each subset of category values (ex: how many cells that have [“has_side”=False, “has_class”=False, “has_segment”=False, “has_type”=False, “has_group”=False] and so on).
bool_ids = list(has_categs.values())
#boolean dataframe from concatenating the boolean series
annotations_bool = pd.concat(bool_ids, axis=1, ignore_index=False, names="ID").fillna(
"N/A"
)
#group the annotations dataframe by the categories and get the number of cells for each subset of category values
bool_counts = annotations_bool.groupby(bool_ids).size()
print(annotations_bool)
print(bool_counts)
has_side has_class has_segment has_type has_group
skids
2015233 True True True True False
1548290 True False True False False
1318919 True True True True True
2015241 True True True True False
1646603 True False True False False
... ... ... ... ... ...
1302513 True True True False False
1630186 True False True False False
1441779 True False True False False
1671147 True True True True False
1048573 True True True False False
[2701 rows x 5 columns]
has_side has_class has_segment has_type has_group
False False False False False 2
True False False 1
True True False False 1
True False 1
True False False False False 3
True False False 908
True 18
True False 6
True 2
True True False False 533
True 437
True False 595
True 194
dtype: int64
#generate the upsetplot of the grouped dataframe and save it
plot(bool_counts)
plt.savefig(folder / "broad_categs_upsetplot.png")
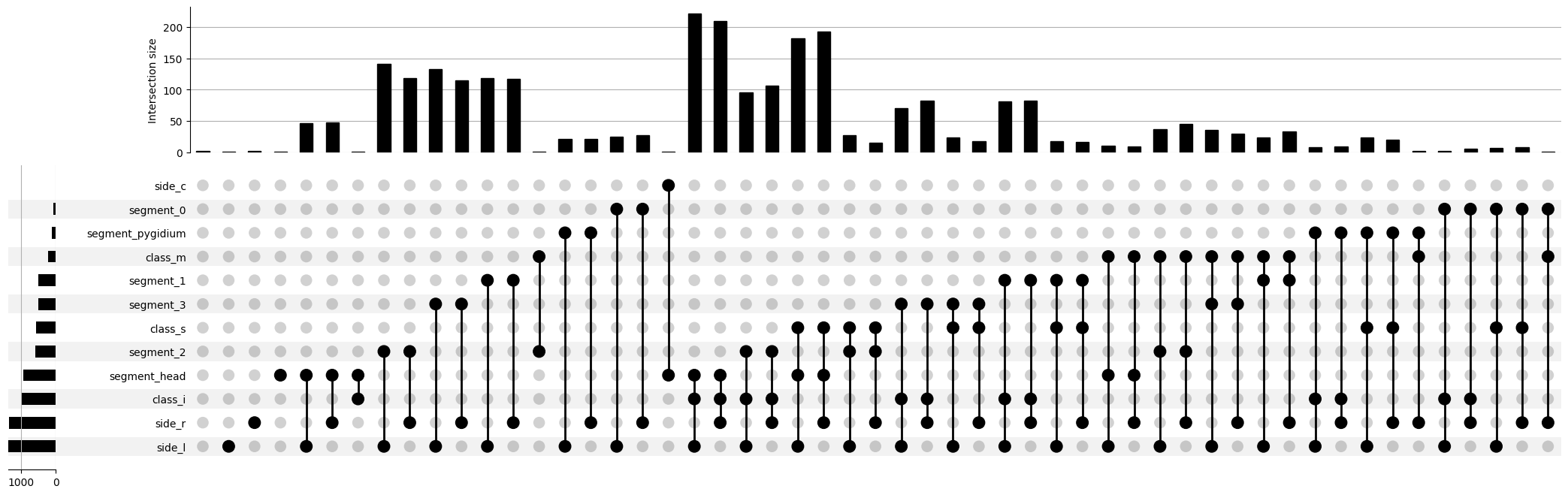
We start generating the second upsetplot by using the following function, which determines if all the skids have the particular name within the particular category
#returns boolean pandas series: True if element=name, else False
def has_element(annotations, category="side", name="l"):
has_element = []
series_name = "{}_{}".format(category, name)
for val in annotations[category]:
if val == name:
has_element.append(True)
else:
has_element.append(False)
return pd.Series(index=annotations["skids"], data=has_element, name=series_name)
For this upsetplot, we just consider the values that can be passed by the categories side, class and segment, and splice the keys based on the category so we can retrieve the values we want to pass in
#generate boolean pandas series for the different names within their respective category
has_sides = {"has_left": None, "has_right": None, "has_center": None}
for key in has_sides:
has_sides[key] = has_element(annotations, category="side", name=key.split("_")[1][0])
has_classes = {"has_sensory": None, "has_inter": None, "has_motor": None}
for key in has_classes:
has_classes[key] = has_element(annotations, category="class", name=key.split("_")[1][0])
has_segments = {"has_seg0": None, "has_seg1": None, "has_seg2": None, "has_seg3": None}
for key in has_segments:
has_segments[key] = has_element(annotations, category="segment", name=key[-1])
has_hp = {"has_head": None, "has_pygidium": None}
for key in has_hp:
has_hp[key]= has_element(annotations, category="segment", name=key.split("_")[1])
has_all = has_sides | has_classes | has_segments | has_hp
bool_ids = list(has_all.values())
#boolean dataframe from concatenating the boolean series
annotations_bool = pd.concat(bool_ids, axis=1, ignore_index=False, names="ID").fillna(
"N/A"
)
#group the annotations dataframe by the names and get the number of cells for each subset of names
bool_counts = annotations_bool.groupby(bool_ids).size()
#generate the upsetplot of the grouped dataframe
plot(bool_counts)
plt.savefig(folder / "sub_categs_upsetplot.png")